Esse artigo é sobre a implementação do Word2vec no TensorFlow. Word2vec é um par de modelos de aprendizado não supervisionado para criação de uma representação vetorial de palavras presentes em textos que usam linguagem natural. A representação é condicionada à distribuição do texto e apresenta características semânticas. Palavras com significado similar tem vetores próximos e operações aritméticas formam expressões que fazem sentido. Nesse artigo, o Word2vec é usado em uma aplicação para consulta de palavras similares.
Código
Para executar o Notebook:
Linux (ou Mac), executar no terminal os comandos abaixo. O último comando inicia o servidor do Jupyter que fica executando (Ctrl-C para terminar). Ele abre automaticamente um navegador com a lista de arquivos do projeto. Para acessar o notebook, entre na pasta
NLPe abra o arquivoWord2vec.ipynb.$ git clone https://github.com/cirocavani/tensorflow-jupyter.git $ cd tensorflow-jupyter $ ./setup.sh $ bin/jupyter-notebook
O código mostrado nesse artigo é autocontido e muito similar ao do Notebook, ou seja, pode ser executado passo a passo (necessário Python3 e TensorFlow).
Esse código foi testado na versão 1.2.1 do TensorFlow.
…
Motivação
Uma das características mais interessantes de Deep Learning é a composição de diferentes componentes em arquiteturas mais sofisticadas. A representação vetorial de palavras (Word Embedding) é um desses componentes que é muito usado em NLP com Deep Learning. As palavras são símbolos discretos da linguagem que podem ser combinados em expressões que tem estrutura e significado. No interesse de aprender algoritmos que sejam capazes de interpretar e compreender essas expressões, é necessário codificar essa informação de forma adequada. Transformar a esparsidade de símbolos da linguagem em uma representação vetorial contínua que absorve características da linguagem é uma dessas codificações.
Nesse artigo, o objetivo é explorar o par de modelos do Word2vec introduzido no paper Efficient Estimation of Word Representations in Vector Space. Em artigos futuros, a ideia é explorar variações desses modelos e fazer uso da técnica de Word Embedding em arquiteturas mais complexas de Deep Learning.
Introdução
(veja as referências para o equacionamento do modelo probabilístico, Aula de Stanford tem mais detalhes)
O Word2vec consiste em dois modelos de aprendizado não supervisionado: o Continuous Bag-of-Words (CBOW) e o Continuous Skip-gram (Skip-gram). Em ambos, o aprendizado é feito sobre o texto em linguagem natural que é processado através de uma janela de tamanho fixo que se desloca palavra a palavra, sempre considerando uma palavra no centro em função das demais palavras do contexto. No CBOW, todas as palavras do contexto são combinadas para predizer a palavra do centro. No Skip-gram, a palavra do cento é usada para predizer alguma das palavras do contexto.
A menos do sentido em que é feita a predição (seja predizer um do contexto a partir do centro ou o centro a partir do contexto), a formulação de modelo probabilístico é similar. O aprendizado consiste em maximizar a probabilidade do que se está predizendo condicionada pela observação da evidência.
A distribuição de probabilidade é calculada usando uma camada única com todas as palavras, consistindo do Logistic Regression com Softmax sobre todas as palavras possíveis. A entrada consiste do vetor médio das palavras do contexto (CBOW) ou direto do vetor da palavra do centro. A saída é a distribuição de probabilidade sobre todas as palavras possíveis (Softmax). O erro é calculado usando Cross Entropy com a palavra do centro (CBOW) ou uma das palavras do contexto (Skip-gram). O erro é usado para ajustar os pesos do Logistic Regression e dos vetores das palavras.
Esse artigo mostra como ambos os modelos são implementados com TensorFlow e como usar a representação vetorial em uma aplicação simples.
Esse tabalho é dividido nos tópicos:
-
Transformação do dataset, uma amostra de ‘texto limpo’ gerado a partir da Wikipedia, no formato usado no modelo.
Continuous Bag-of-Words (CBOW)
Função de entrada de dados e grafo do modelo de aprendizado do primeiro modelo do Word2vec.
Continuous Skip-gram (Skip-gram)
Função de entrada de dados e grafo do modelo de aprendizado do segundo modelo do Word2vec.
-
Aplicação de consulta a palavras similares usando a representação vetorial.
-
Especificação do treinamento, visualização usando TensorBoard.
-
Considerações sobre a implementação e próximos assuntos.
-
Links do material em que esse trabalho foi baseado.
Módulos necessários para o código presente nesse artigo:
import collections
import os
import random
import requests
import zipfile
import tensorflow as tf
import numpy as np
tf.logging.set_verbosity(tf.logging.ERROR)
Preparação dos Dados
O treinamento do Word2vec é feito com texto em linguagem natural. A representação vetorial fica condicionada à distribuição das palavras no texto. Isso significa que as relações entre os vetores pode ser boa se o texto tiver evidencias suficientes para reforçar esse vínculo, de outra forma, os vetores são reflexo do texto.
Para esse trabalho, o dataset usado é uma amostra de texto gerada a partir da Wikipedia. O texto só tem palavras sem segmentação (pontuação, formatação). Esse dataset foi escolhido por ser fácil de trabalhar e pode não ser a melhor escolha para se obter o estado-da-arte nessa tarefa.
Para obter bons resultados com Word Embedding em determinados domínios, é importante ter um dataset que seja representativo.
Clean Text (text8) from Wikipedia
[ Site ] [ text8.zip ] (~30MB)
Relationship of Wikipedia Text to Clean Text
(June 11, 2006) Abstract: The entropy of “clean” written English, in a 27 character alphabet containing only the letters a-z and nonconsecutive spaces, has been estimated to be between 0.6 and 1.3 bits per character [3,8] . We find that most of the best compressors will compress Wikipedia text (enwik9, 1 GB) and equivalent cleaned text (fil9, 715 MB) to about the same ratio, usually within 3% of each other. Low end compressors will compress clean text about 5% smaller. Furthermore, a quick test on 100 MB of cleaned text (text8) will predict a compression ratio that is about 2% to 4% below the true ratio on fil9 for most compressors. (…)
O processo consiste em:
- Definição do vocabulário: conjunto das palavras mais comuns, cada palavra recebe um número / índice
- Transformação do texto da sequencia de palavras na sequencia de números do vocabulário
…
Vocabulário
O propósito do vocabulário é codificar as palavras em números que são usados como índices da matriz que contém os vetores que representam as palavras. O texto, sequencia de palavras, é transformado na sequencia de números correspondente usando o dicionário do vocabulário. Essa é uma transformação necessária tanto para o aprendizado no treinamento quanto para a inferência (consulta de similaridade).
Apenas palavras presentes nesse vocabulário são ‘conhecidas’ pelo modelo.
O dataset text8 tem 17.005.207 palavras no total, com 253.854 palavras únicas. Considerando apenas palavras com pelo menos 10 ocorrências, tem-se 47.134 palavras únicas.
Nesse caso, o vocabulário é construído com as 50 mil palavras que tem maior ocorrência e cada uma recebe um identificador, correspondendo à posição na ordem do número de ocorrências.
As palavras que não fazem parte do vocabulário são mapeadas como ‘unknown’. No dataset, são 203.855 palavras únicas mapeadas para ‘unknown’, correspondendo a 418.391 ocorrências no total.
Trecho do texto:
anarchism originated as a term of abuse first used against early working class radicals including the diggers of the english revolution and the sans culottes of the french revolution whilst the term is still used in a pejorative way to describe any act that used violent means to destroy the organization of society it has also been taken up as a positive label by self defined anarchists the word anarchism is derived from the greek without archons ruler chief king anarchism as a political philosophy is the belief that rulers are unnecessary and should be abolished although there are differing interpretations of what this means anarchism also refers to related social movements that advocate the elimination of authoritarian institutions particularly the state the word anarchy as most anarchists use it does not imply chaos nihilism or anomie but rather a harmonious anti authoritarian society in place of what are regarded as authoritarian political structures and coercive economic instituti…
Palavras mais frequentes:
the(1.061.396)of(593.677)and(416.629)one(411.764)in(372.201)a(325.873)to(316.376)zero(264.975)nine(250.430)two(192.644)
Amostra de palavras com apenas uma ocorrência (mapeadas como ‘unknown’):
kajn, gorbacheva, mikhailgorbachev, englander, workmans, erniest, metzada, metzuda, fretensis, exortation, …
Construção do vocabulário:
word_to_id: Dict[str, int]- dicionário que mapeia a palavra no identificador (índice)word_from_id: Dict[int, str]- dicionário reverso que mapeia o identificador (índice) na palavra
r = requests.get('http://mattmahoney.net/dc/text8.zip', stream=True)
with open('text8.zip', 'wb') as f:
for chunk in r.iter_content(chunk_size=32768):
if chunk:
f.write(chunk)
with zipfile.ZipFile('text8.zip') as f:
raw_text = f.read(f.namelist()[0]).decode('utf-8')
words = raw_text.split()
words_freq = collections.Counter(words).most_common()
vocabulary_size = 50_000
words_vocab = words_freq[:(vocabulary_size-1)]
UNK_ID = 0
word_to_id = dict((word, word_id)
for word_id, (word, _) in enumerate(words_vocab, UNK_ID+1))
word_to_id['UNK'] = UNK_ID
word_from_id = dict((word_id, word) for word, word_id in word_to_id.items())
with open('vocabulary.txt', 'w') as f:
for word_id in range(vocabulary_size):
f.write(word_from_id[word_id] + '\n')
Depois de executar esse código, as variáveis word_to_id e word_from_id correspondem ao vocabulário das palavras conhecidas. O arquivo vocabulary.txt armazena as palavras na mesma ordem dos índices e deve ser usado para carregar o vocabulário na forma das variáveis anteriores (sem precisar reprocessar o dataset).
Transformação do Texto
Por conveniência para esse trabalho, a transformação do texto é feita apenas em memória.
Depois da transformação, a lista de identificadores (índices) preserva o mesmo número de palavras do texto original, 17.005.207 itens.
Transformação:
data: List[int]- lista dos índices correspondentes às palavras definidas no vocabulário
data = list(word_to_id.get(word, UNK_ID) for word in words)
Depois de executar esse código, a variável data corresponde ao texto usando os índices ao invés de palavras.
Trecho inicial com os índices (10 primeiros itens de data):
[5234, 3081, 12, 6, 195, 2, 3134, 46, 59, 156]
Trecho equivalente com as palavras:
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against']
…
Ao final do procedimento descrito nesse tópico, 4 resultados são produzidos:
word_to_id: Dict[str, int]- dicionário que mapeia a palavra no identificador (índice)word_from_id: Dict[int, str]- dicionário reverso que mapeia o identificador (índice) na palavradata: List[int]- lista dos índices correspondentes às palavras definidas no vocabuláriovocabulary.txt- arquivo com as palavras na mesma ordem dos índices
Na sequencia, o código necessário para aprender a representação vetorial é desenvolvido para os dois modelos.
Continuous Bag-of-Words (CBOW)
O CBOW é o modelo do Word2vec que maximiza a probabilidade de predizer a palavra do centro a partir da observação das palavras do contexto em uma janela de palavras que desliza sobre o texto. Para calcular essa probabilidade, é usada uma camada única que tem como entrada a média dos vetores das palavras do contexto e a probabilidade de cada palavras possíveis como saída. O erro é calculado pela diferença entre a distribuição de probabilidade da saída e a palavra do centro. Os pesos do modelo e dos vetores das palavras são corrigidos pelo gradiente.
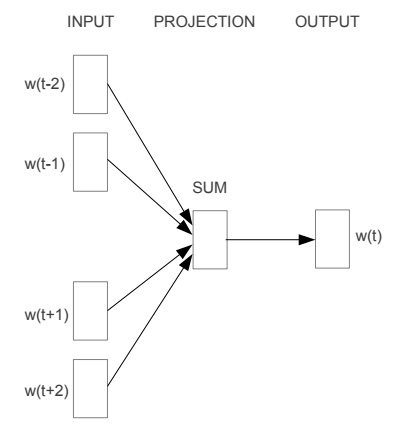
(imagem do paper Efficient Estimation of Word Representations in Vector Space)
O processo consiste em:
- Função de Entrada: função que percorre os dados criando lotes (batches) de entrada e saída para treinar o modelo usando gradiente
- Grafo do Modelo: descrição das operações que definem o fluxo e transformações dos dados para cálculo do erro (esse grafo permite que o TensorFlow calcule o gradiente e atualize as variáveis)
…
Entrada
Para o treinamento do CBOW, dada uma janela, a entrada consiste das palavras do contexto (todas as palavras menos o centro) e a saída, somente a palavra do centro. A janela é uma sequencia de tamanho fixo de palavras do texto. As janelas correspondem ao deslocamento palavra a palavra sobre o texto.
O processamento é feito com data que contém a lista de índices das palavras.
Seja:
$n$o tamanho dedata(no código,num_words)$m$o tamanho do lote (no código,batch_size)$k$o tamanho da janela (no código,window_size)
Então:
Possíveis tamanhos da janela:
$ k \in \{2i + 1 \mid i \in \mathbb{N}^+, i \le (n - m) / 2 \} $(número ímpar maior que 3 menor que um lote)
Número de janelas de tamanho
$k$em uma época é (no código,num_windows):$ p = n - k + 1 $(a primeira janela tem
$k$itens, restando$n - k$itens para novas janelas)Número de lotes por época é (no código,
num_batches):$ t = \lfloor p / m \rfloor $(até
$m-1$janelas do final podem não fazer parte de um batch)Índice do centro de uma janela é (no código,
target_index):$ i = \lfloor k / 2 \rfloor $(
$k$é impar)
Código:
def context_window(window_words, target_index):
words = list(window_words)
del words[target_index]
return words
def input_cbow(data, batch_size, window_size):
if window_size % 2 == 0 or window_size < 3 \
or window_size > (len(data) - batch_size) / 2:
# {window_size} must be odd: (n words left) target (n words right)
raise Exception(
'Invalid parameters: window_size must be a small odd number')
num_words = len(data)
num_windows = num_words - window_size + 1
num_batches = num_windows // batch_size
target_index = window_size // 2
words = collections.deque(data[window_size:])
window_words = collections.deque(data[:window_size], maxlen=window_size)
for n in range(num_batches):
batch = np.ndarray(shape=(batch_size, window_size-1), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
for i in range(batch_size):
batch[i,:] = context_window(window_words, target_index)
labels[i, 0] = window_words[target_index]
window_words.append(words.popleft())
yield batch, labels
Exemplo:
batch_size = 2
window_size = 3
num_iters = 2
num_words = window_size + num_iters * batch_size - 1
text = ' '.join(word_from_id[word_id] for word_id in data[:num_words])
print('Text\n\n', text, '\n')
data_iter = input_cbow(data, batch_size, window_size)
for k in range(1, num_iters+1):
print('Batch {}\n'.format(k))
batch_context, batch_target = next(data_iter)
for i in range(batch_size):
context_words = ', '.join(
word_from_id[word_id] for word_id in batch_context[i, :])
target_word = word_from_id[batch_target[i, 0]]
print('[{}] -> {}'.format(context_words, target_word))
print()
Text
anarchism originated as a term of
Batch 1
[anarchism, as] -> originated
[originated, a] -> as
Batch 2
[as, term] -> a
[a, of] -> term
…
Modelo
Para o treinamento do CBOW, o erro é calculado para a predição da palavra do centro usando Softmax sobre todas as palavras possíveis, a partir da média das palavras do contexto. O grafo consiste em receber os índices das palavras do contexto, transformar esses índices nos vetores correspondentes, calcular a média, fazer a projeção linear da dimensão dos vetores para o número de palavras possíveis, calcular a distribuição de probabilidade e calcular a diferença com o índice da palavra alvo (centro). Esse processamento é feito em lote. O TensorFlow faz o cálculo do gradiente e propaga as correções para as variáveis do modelo (vetores de palavras e projeção).
O número de palavas possíveis (classes do Softmax) é considerável e torna o cálculo exato do erro computacionalmente caro. Uma forma de tornar esse problema tratável é usando amostra de algumas classes e fazer o cálculo do erro aproximado.
O TensorFlow já tem a implementação desse cálculo na função tf.nn.sampled_softmax_loss.
Construção do modelo:
Objetos do TensorFlow necessários para construção e execução do grafo.
tf.InteractiveSession assume a função geral de execução, facilitando evolução incremental.
graph = tf.Graph()
graph.as_default()
session = tf.InteractiveSession(graph=graph)
Parâmetros:
batch_size: número de exemplos a serem processados no cálculo do erro (médio)context_size: número de palavras do contexto em cada exemplovocabulary_size: número de palavras possíveis (todos os índices são menores que esse valor)embedding_size: dimensão do vetor de representação das palavrasnum_sampled: número de classes amostrada para aproximação do erro
batch_size = 4
context_size = 2
vocabulary_size = 20
embedding_size = 3
num_sampled = 2
X representa o tensor de entrada com dimensões (batch_size, context_size), ou seja, uma matriz em que cada linha contém um exemplo com o índice das palavras do contexto (todos menores que vocabulary_size).
No treinamento, esse tensor é gerado com a Função de Entrada aplicada aos dados e fornecido para o grafo.
X = tf.constant(np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size, context_size),
dtype=np.int32))
print(X, '\n')
print(X.eval())
Tensor("Const:0", shape=(4, 2), dtype=int32)
[[ 1 17]
[16 14]
[12 10]
[ 0 17]]
y representa o tensor da saída esperada com dimensões (batch_size, 1), ou seja, uma matriz coluna em que cada linha contém o índice da palavra do centro (todos menores que vocabulary_size) correspondente ao exemplo em X.
No treinamento, esse tensor é gerado com a Função de Entrada aplicada aos dados e fornecido para o grafo.
y = tf.constant(np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size, 1),
dtype=np.int32))
print(y, '\n')
print(y.eval())
Tensor("Const_1:0", shape=(4, 1), dtype=int32)
[[15]
[ 7]
[ 5]
[11]]
embeddings é o tensor da representação vetorial das palavras com dimensões (vocabulary_size, embedding_size), ou seja, uma matriz com uma linha para cada índice das palavras possíveis e com o número de colunas igual a dimensão do espaço vetorial das palavras. O tamanho do espaço vetorial (embedding_size) é um hiperparâmetro que deve ser ajustado (hyperparameters tuning).
Esse tensor é uma variável do modelo que é ajustada pelo TensorFlow durante o treinamento.
# ~ tf.random_uniform(shape=(vocabulary_size, embedding_size),
# minval=-1.0, maxval=1.0)
embeddings = tf.Variable(
2 * np.random.rand(vocabulary_size, embedding_size) - 1, dtype=tf.float32)
embeddings.initializer.run()
print(embeddings, '\n')
print(embeddings.eval())
<tf.Variable 'Variable:0' shape=(20, 3) dtype=float32_ref>
[[ 0.02465968 0.0272339 0.69104964]
[ 0.72243339 -0.24764678 0.90138841]
[-0.18978444 -0.49418542 -0.82074291]
[ 0.19964993 -0.96849972 0.85506338]
[-0.16671634 -0.32576984 -0.18718871]
[-0.89501756 -0.08256974 0.46944314]
[ 0.14423893 -0.28027847 0.92462093]
[ 0.24059331 -0.45933899 -0.79792535]
[ 0.0379599 0.40385354 0.61720735]
[ 0.16235992 -0.71082664 -0.59583354]
[-0.19639543 0.62178326 -0.76987004]
[-0.93682903 0.61401904 -0.93552113]
[ 0.06768601 0.82978565 0.88071883]
[ 0.08320533 0.0010252 -0.91865432]
[ 0.99165189 0.25646555 0.94810784]
[-0.52318448 -0.61726421 0.62240851]
[-0.80972534 -0.17265365 0.30722952]
[ 0.7482543 0.07703447 -0.00715398]
[ 0.276692 0.96886969 -0.03008272]
[ 0.14041884 0.93725801 -0.93065017]]
X_embed é o tensor com os vetores das palavras correspondentes à entrada X, tem dimensões (batch_size, context_size, embedding_size). A função tf.nn.embedding_lookup recebe os tensores da representação vetorial e dos índices da entrada e retorna um tensor em que os índices são substituídos pelos vetores correspondentes.
X_embed = tf.nn.embedding_lookup(embeddings, X)
print(X_embed, '\n')
print(X_embed.eval())
Tensor("embedding_lookup:0", shape=(4, 2, 3), dtype=float32)
[[[ 0.72243339 -0.24764678 0.90138841]
[ 0.7482543 0.07703447 -0.00715398]]
[[-0.80972534 -0.17265365 0.30722952]
[ 0.99165189 0.25646555 0.94810784]]
[[ 0.06768601 0.82978565 0.88071883]
[-0.19639543 0.62178326 -0.76987004]]
[[ 0.02465968 0.0272339 0.69104964]
[ 0.7482543 0.07703447 -0.00715398]]]
X_avg é o tensor com a média dos vetores das palavras de X_embed, tem dimensão (batch_size, embedding_size), ou seja, uma matriz em que cada linha é a soma dos vetores das palavras do contexto de um exemplo dividida pelo número de palavras do contexto. A função tf.reduce_mean recebe o tensor com os vetores das palavras e calcula a média na dimensão especificada (correspondente ao número de palavras do contexto).
X_avg = tf.reduce_mean(X_embed, axis=1)
print(X_avg, '\n')
print(X_avg.eval())
Tensor("Mean:0", shape=(4, 3), dtype=float32)
[[ 0.73534381 -0.08530615 0.44711721]
[ 0.09096327 0.04190595 0.62766868]
[-0.06435471 0.72578442 0.05542439]
[ 0.386457 0.05213419 0.34194782]]
O código a seguir é uma ‘inspeção’ do cálculo da média, não faz parte do modelo.
Fazendo o corte da primeira posição de cada vetor de palavras do contexto do primeiro exemplo, fica fácil visualizar como o cálculo da média é feito.
$$ \text{X_avg}[0, 0] = \frac{\text{X_embed}[0, 0, 0] + \text{X_embed}[0, 1, 0]}{2} = \frac{0.723 + 0.748}{2} = 0.735 $$
c0_w0 = X_embed[0,:,0].eval()
print('first dimension of each verctor of first context:\n\n', c0_w0, '\n')
print('first dimension avarage:\n\n', np.mean(c0_w0))
first dimension of each verctor of first context:
[ 0.72243339 0.7482543 ]
first dimension avarage:
0.735344
W é o tensor da camada de predição com dimensões (vocabulary_size, embedding_size), ou seja, uma matriz em que cada linha corresponde aos pesos que correlaciona uma palavra possível com a representação vetorial das palavras. Esse tensor é usado no cálculo da distribuição de probabilidade (Softmax).
Esse tensor é uma variável do modelo que é ajustada pelo TensorFlow durante o treinamento.
# ~ tf.truncated_normal(shape=(vocabulary_size, embedding_size),
# stddev=1.0 / np.sqrt(embedding_size))
W = tf.Variable(
np.random.randn(vocabulary_size, embedding_size) / np.sqrt(embedding_size),
dtype=tf.float32)
W.initializer.run()
print(W)
<tf.Variable 'Variable_1:0' shape=(20, 3) dtype=float32_ref>
b é o tensor bias da camada de predição com dimensão vocabulary_size. Esse tensor é usado no cálculo da distribuição de probabilidade (Softmax).
Esse tensor é uma variável do modelo que é ajustada pelo TensorFlow durante o treinamento.
b = tf.Variable(np.zeros(vocabulary_size), dtype=tf.float32)
b.initializer.run()
print(b)
<tf.Variable 'Variable_2:0' shape=(20,) dtype=float32_ref>
sampled_loss é o tensor com o erro de classificação do modelo (diferença entre a saída esperada y e a predição usando Softmax), tem dimensão batch_size. A função tf.nn.sampled_softmax_loss recebe as variáveis do Softmax, o vetor médio da entrada e a saída esperada para fazer o cálculo aproximado do erro de classificação (otimização para diminuir o custo computacional do treinamento).
sampled_loss = tf.nn.sampled_softmax_loss(weights=W,
biases=b,
inputs=X_avg,
labels=y,
num_sampled=num_sampled,
num_classes=vocabulary_size)
print(sampled_loss, '\n')
print(sampled_loss.eval())
Tensor("Reshape_2:0", shape=(4,), dtype=float32)
[ 0.97429556 1.18274236 1.48677433 0.95192599]
loss é o tensor do erro médio (escalar). A partir desse tensor, o TensorFlow faz o cálculo do gradiente e propaga as correções para as variáveis do modelo embeddings, W e b.
loss = tf.reduce_mean(sampled_loss)
print(loss, '\n')
print(loss.eval())
Tensor("Mean_1:0", shape=(), dtype=float32)
0.896208
Limpeza das variáveis usadas nessa construção.
session.close()
del X, y, embeddings, X_embed, X_avg, c0_w0, W, b, sampled_loss, loss
del graph, session
Grafo do Modelo:
Os tensores de entrada X e y são substituídos por placeholder que são fornecidos no momento da execução. O tamanho do lote (batch_size) e do contexto (context_size) são substituídos por None, indicando uma dimensão não pré-definida, conhecida durante a execução. Por fim, os valores gerados usando NumPy são substituídos pelos equivalentes do TensorFlow (tornando a representação serializada do grafo independente do Python).
A normalização de
embeddingsé discutida no tópico de Nearest Neighbors.
def model_cbow(vocabulary_size, embedding_size, num_sampled):
X = tf.placeholder_with_default([[0]], shape=(None, None), name='X')
y = tf.placeholder_with_default([[0]], shape=(None, 1), name='y')
embeddings = tf.Variable(
tf.random_uniform(shape=(vocabulary_size, embedding_size),
minval=-1.0, maxval=1.0),
name='embeddings')
X_embed = tf.nn.embedding_lookup(embeddings, X)
X_avg = tf.reduce_mean(X_embed, axis=1)
softmax_weights = tf.Variable(
tf.truncated_normal(shape=(vocabulary_size, embedding_size),
stddev=1.0 / np.sqrt(embedding_size)),
name='W')
softmax_biases = tf.Variable(
tf.zeros(shape=(vocabulary_size,)),
name='b')
with tf.name_scope('loss'):
sampled_loss = tf.nn.sampled_softmax_loss(weights=softmax_weights,
biases=softmax_biases,
inputs=X_avg,
labels=y,
num_sampled=num_sampled,
num_classes=vocabulary_size)
loss = tf.reduce_mean(sampled_loss, name='mean')
norm = tf.norm(embeddings, axis=1, keep_dims=True)
normalized_embeddings = embeddings / norm
return X, y, normalized_embeddings, loss
Exemplo:
batch_size = 4
context_size = 2
vocabulary_size = 20
embedding_size = 3
num_sampled = 2
with tf.Graph().as_default() as graph, \
tf.Session(graph=graph) as session:
X, y, embeddings, loss_op = model_cbow(vocabulary_size,
embedding_size,
num_sampled)
tf.global_variables_initializer().run()
X_batch = np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size, context_size),
dtype=np.int32)
y_batch = np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size, 1),
dtype=np.int32)
feed_data = {X: X_batch, y: y_batch}
loss, embeddings_ = session.run([loss_op, embeddings], feed_dict=feed_data)
print('Avarage loss: {:,.3f}\n'.format(loss))
print(embeddings_)
Avarage loss: 0.643
[[-0.41934049 0.87780112 0.23155731]
[-0.74620527 0.19323198 0.63705504]
[-0.93713832 -0.03107116 -0.34757251]
[ 0.13247947 -0.33423916 0.93313104]
[-0.3245635 0.94457054 -0.04944721]
[ 0.42800939 -0.6734488 -0.60272276]
[ 0.62396824 0.29471466 0.72374505]
[ 0.25484443 0.80637228 -0.53368354]
[ 0.15220016 0.77104568 0.61832321]
[ 0.59362125 0.78019625 0.19724993]
[-0.4242104 0.65139139 0.62907463]
[ 0.60960639 0.62361234 0.48937491]
[-0.22752148 -0.89166701 0.39136165]
[-0.53129029 0.71622092 0.45250228]
[ 0.91685665 0.06816136 -0.39335477]
[-0.06128841 0.98920041 0.13313945]
[ 0.53842431 0.50408977 -0.67527241]
[-0.28058326 -0.8536973 0.43871868]
[-0.83915943 0.12548649 0.52921134]
[ 0.21840763 -0.26360065 0.93958122]]
…
Ao final do procedimento descrito nesse tópico, 2 resultados são produzidos:
input_cbow(data: List[int], batch_size: int, window_size: int) -> Iterable[Tutple[ndarray, ndarray]]- função que percorre os dados criando lotes (batches) de entrada e saída esperada (essa função é um generator)model_cbow(vocabulary_size: int, embedding_size: int, num_sampled: int) -> Tuple[Tensor, Tensor, Tensor, Tensor]- função que define o fluxo de transformações dos dados para cálculo do erro de predição usada no aprendizado da representação vetorial com TensorFlow
Na sequencia, o mesmo procedimento é feito para o segundo modelo do Word2vec, Skip-gram.
Continuous Skip-gram (Skip-gram)
O Skip-gram é o modelo do Word2vec que maximiza a probabilidade de predizer alguma das palavras do contexto a partir da observação da palavra do centro em uma janela de palavras que desliza sobre o texto. Para calcular essa probabilidade, é usada uma camada única que tem como entrada o vetor da palavra do centro e a probabilidade de cada palavras possíveis como saída. O erro é calculado pela diferença entre a distribuição de probabilidade da saída e a palavra do contexto. Os pesos do modelo e dos vetores das palavras são corrigidos pelo gradiente.
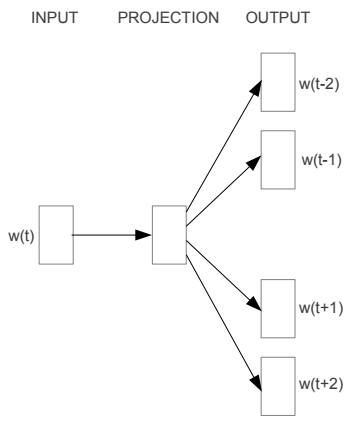
(imagem do paper Efficient Estimation of Word Representations in Vector Space)
O processo consiste em:
- Função de Entrada: função que percorre os dados criando lotes (batches) de entrada e saída para treinar o modelo usando gradiente
- Grafo do Modelo: descrição das operações que definem o fluxo e transformações dos dados para cálculo do erro (esse grafo permite que o TensorFlow calcule o gradiente e atualize as variáveis)
…
Entrada
Para o treinamento do Skip-gram, dada uma janela, a entrada consiste da palavra do cento e a saída, uma das palavras do contexto. A janela é uma sequencia de tamanho fixo de palavras do texto. As janelas correspondem ao deslocamento palavra a palavra sobre o texto.
Formato de um exemplo:
(Palavra do centro, Palavra do Contexto)
Para uma janela de 5 palavras e uma amostra de 4 palavras do contexto, então:
[w1, w2, w3, w4, w5] -> (w3, w1), (w3, w2), (w3, w4), (w3, w5)
Total de 4 pares para uma janela.
Para uma amostra de 2, um resultado possível é:
[w1, w2, w3, w4, w5] -> (w3, w4), (w3, w5)
O processamento é feito com data que contém a lista de índices das palavras.
Seja:
$n$o tamanho dedata(no código,num_words)$m$o tamanho do lote (no código,batch_size)$k$o tamanho da janela (no código,window_size)$s$o tamanho da amostra do contexto (no código,num_skips)
Então:
Possíveis tamanhos da janela:
$ k \in \{2i + 1 \mid i \in \mathbb{N}^+, i \le (n - m) / 2 \} $(número ímpar maior que 3 menor que um lote)
Possíveis tamanhos de amostras do contexto:
$ s \in (0, k) $(contexto tem
$k - 1$palavras)Número de janelas de tamanho
$k$em uma época é (no código,num_windows):$ p = n - k + 1 $(a primeira janela tem
$k$itens, restando$n - k$itens para novas janelas)Número de lotes por época é (no código,
num_batches):$ t = \lfloor p \cdot s / m \rfloor $(cada janela tem
$s$exemplos, até$m-1$exemplos do final podem não fazer parte de um batch)Índice do centro de uma janela é (no código,
target_index):$ i = \lfloor k / 2 \rfloor $(
$k$é impar)
Código:
def context_window(window_words, target_index):
words = list(window_words)
del words[target_index]
return words
def context_sample(context_words, sample_size):
return random.sample(context_words, sample_size)
def context_skips(window_words, target_index, sample_size, use_sample):
words = context_window(window_words, target_index)
if use_sample:
words = context_sample(words, sample_size)
return words
def input_skip_gram(data, batch_size, window_size, num_skips):
if window_size % 2 == 0 or window_size < 3 \
or window_size > (len(data) - batch_size) / 2:
# {window_size} must be odd: (n words left) target (n words right)
raise Exception(
'Invalid parameters: window_size must be a small odd number')
if num_skips > window_size - 1:
# It is not possible to generate {num_skips} different pairs
# with the second word coming from {window_size - 1} words.
raise Exception(
'Invalid parameters: num_skips={}, window_size={}'.format(
num_skips, window_size))
num_words = len(data)
num_windows = num_words - window_size + 1
num_batches = num_windows * num_skips // batch_size
target_index = window_size // 2
use_sample = num_skips < window_size - 1
words = collections.deque(data[window_size:])
window_words = collections.deque(data[:window_size], maxlen=window_size)
target_word = window_words[target_index]
context_words = context_skips(window_words,
target_index,
num_skips,
use_sample)
for n in range(num_batches):
batch = np.ndarray(shape=(batch_size,), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
for i in range(batch_size):
batch[i] = target_word
labels[i, 0] = context_words.pop()
if not context_words:
window_words.append(words.popleft())
target_word = window_words[target_index]
context_words = context_skips(window_words,
target_index,
num_skips,
use_sample)
yield batch, labels
Exemplo:
batch_size = 2
window_size = 3
num_skips = 2
num_iters = 2
num_words = window_size + num_iters * batch_size // num_skips - 1
text = ' '.join(word_from_id[word_id] for word_id in data[:num_words])
print('Text\n\n', text, '\n')
data_iter = input_skip_gram(data, batch_size, window_size, num_skips)
for k in range(1, num_iters+1):
print('Batch {}\n'.format(k))
batch_target, batch_context = next(data_iter)
for i in range(batch_size):
target_word = word_from_id[batch_target[i]]
context_word = word_from_id[batch_context[i, 0]]
print('{} -> {}'.format(target_word, context_word))
print()
Text
anarchism originated as a
Batch 1
originated -> as
originated -> anarchism
Batch 2
as -> a
as -> originated
…
Modelo
Para o treinamento do Skip-gram, o erro é calculado para a predição da palavra do contexto usando Softmax sobre todas as palavras possíveis, a partir da palavra do centro. O grafo consiste em receber o índice da palavra do centro, transformar esses índice no vetor correspondente, fazer a projeção linear da dimensão dos vetores para o número de palavras possíveis, calcular a distribuição de probabilidade e calcular a diferença com o índice da palavra alvo (contexto). Esse processamento é feito em lote. O TensorFlow faz o cálculo do gradiente e propaga as correções para as variáveis do modelo (vetores de palavras e projeção).
O número de palavas possíveis (classes do Softmax) é considerável e torna o cálculo exato do erro computacionalmente caro. Uma forma de tornar esse problema tratável é usando amostra de algumas classes e fazer o cálculo do erro aproximado.
O TensorFlow já tem a implementação desse cálculo na função tf.nn.sampled_softmax_loss.
Construção do modelo:
Objetos do TensorFlow necessários para construção e execução do grafo.
tf.InteractiveSession assume a função geral de execução, facilitando evolução incremental.
graph = tf.Graph()
graph.as_default()
session = tf.InteractiveSession(graph=graph)
Parâmetros:
batch_size: número de exemplos a serem processados no cálculo do erro (médio)vocabulary_size: número de palavras possíveis (todos os índices são menores que esse valor)embedding_size: dimensão do vetor de representação das palavrasnum_sampled: número de classes amostrada para aproximação do erro
batch_size = 4
vocabulary_size = 20
embedding_size = 3
num_sampled = 2
X representa o tensor de entrada com dimensão batch_size, ou seja, um vetor em que elemento contém um exemplo com o índice da palavra do centro (todos menores que vocabulary_size).
No treinamento, esse tensor é gerado com a Função de Entrada aplicada aos dados e fornecido para o grafo.
X = tf.constant(np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size,),
dtype=np.int32))
print(X, '\n')
print(X.eval())
Tensor("Const:0", shape=(4,), dtype=int32)
[ 0 18 8 2]
y representa o tensor da saída esperada com dimensões (batch_size, 1), ou seja, uma matriz coluna em que cada linha contém o índice da palavra do contexto (todos menores que vocabulary_size) correspondente ao exemplo em X.
No treinamento, esse tensor é gerado com a Função de Entrada aplicada aos dados e fornecido para o grafo.
y = tf.constant(np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size, 1),
dtype=np.int32))
print(y, '\n')
print(y.eval())
Tensor("Const_1:0", shape=(4, 1), dtype=int32)
[[ 3]
[ 2]
[ 6]
[13]]
embeddings é o tensor da representação vetorial das palavras com dimensões (vocabulary_size, embedding_size), ou seja, uma matriz com uma linha para cada índice das palavras possíveis e com o número de colunas igual a dimensão do espaço vetorial das palavras. O tamanho do espaço vetorial (embedding_size) é um hiperparâmetro que deve ser ajustado (hyperparameters tuning).
Esse tensor é uma variável do modelo que é ajustada pelo TensorFlow durante o treinamento.
# ~ tf.random_uniform(shape=(vocabulary_size, embedding_size),
# minval=-1.0, maxval=1.0)
embeddings = tf.Variable(
2 * np.random.rand(vocabulary_size, embedding_size) - 1, dtype=tf.float32)
embeddings.initializer.run()
print(embeddings, '\n')
print(embeddings.eval())
<tf.Variable 'Variable:0' shape=(20, 3) dtype=float32_ref>
[[-0.22159426 -0.81183708 0.28478935]
[ 0.76308548 -0.79328871 0.09497505]
[-0.68044358 0.21237929 0.73750448]
[-0.34718159 -0.15143529 -0.04712906]
[ 0.27602258 -0.23773642 0.33447248]
[-0.01182473 -0.17109098 0.02682818]
[ 0.7545014 -0.88493699 -0.93377852]
[ 0.79372334 -0.2756415 -0.92131668]
[-0.02907605 0.42701542 0.72997206]
[-0.92163646 -0.85631901 0.94028205]
[ 0.98649979 -0.47456205 0.51289463]
[-0.6709975 -0.10597651 0.18936852]
[ 0.07194393 0.9841823 0.77935523]
[ 0.86171913 -0.9591046 0.28345126]
[-0.09288186 0.05495871 -0.07961052]
[ 0.90613997 -0.38930881 0.29475355]
[-0.0820492 -0.75468153 -0.97437572]
[ 0.39236537 -0.287498 0.5520497 ]
[ 0.75215852 -0.86795551 0.86454004]
[-0.6033932 0.84885919 0.75979698]]
X_embed é o tensor com os vetores das palavras correspondentes à entrada X, tem dimensões (batch_size, embedding_size). A função tf.nn.embedding_lookup recebe os tensores da representação vetorial e dos índices da entrada e retorna um tensor em que os índices são substituídos pelos vetores correspondentes.
X_embed = tf.nn.embedding_lookup(embeddings, X)
print(X_embed, '\n')
print(X_embed.eval())
Tensor("embedding_lookup:0", shape=(4, 3), dtype=float32)
[[-0.22159426 -0.81183708 0.28478935]
[ 0.75215852 -0.86795551 0.86454004]
[-0.02907605 0.42701542 0.72997206]
[-0.68044358 0.21237929 0.73750448]]
W é o tensor da camada de predição com dimensões (vocabulary_size, embedding_size), ou seja, uma matriz em que cada linha corresponde aos pesos que correlaciona uma palavra possível com a representação vetorial das palavras. Esse tensor é usado no cálculo da distribuição de probabilidade (Softmax).
Esse tensor é uma variável do modelo que é ajustada pelo TensorFlow durante o treinamento.
# ~ tf.truncated_normal(shape=(vocabulary_size, embedding_size),
# stddev=1.0 / np.sqrt(embedding_size))
W = tf.Variable(
np.random.randn(vocabulary_size, embedding_size) / np.sqrt(embedding_size),
dtype=tf.float32)
W.initializer.run()
print(W)
<tf.Variable 'Variable_1:0' shape=(20, 3) dtype=float32_ref>
b é o tensor bias da camada de predição com dimensão vocabulary_size. Esse tensor é usado no cálculo da distribuição de probabilidade (Softmax).
Esse tensor é uma variável do modelo que é ajustada pelo TensorFlow durante o treinamento.
b = tf.Variable(np.zeros(vocabulary_size), dtype=tf.float32)
b.initializer.run()
print(b)
<tf.Variable 'Variable_2:0' shape=(20,) dtype=float32_ref>
sampled_loss é o tensor com o erro de classificação do modelo (diferença entre a saída esperada y e a predição usando Softmax), tem dimensão batch_size. A função tf.nn.sampled_softmax_loss recebe as variáveis do Softmax, o vetor da palavra do centro na entrada e a saída esperada para fazer o cálculo aproximado do erro de classificação (otimização para diminuir o custo computacional do treinamento).
sampled_loss = tf.nn.sampled_softmax_loss(weights=W,
biases=b,
inputs=X_embed,
labels=y,
num_sampled=num_sampled,
num_classes=vocabulary_size)
print(sampled_loss, '\n')
print(sampled_loss.eval())
Tensor("Reshape_2:0", shape=(4,), dtype=float32)
[ 1.1068728 1.28189397 1.29348147 0.94145703]
loss é o tensor do erro médio (escalar). A partir desse tensor, o TensorFlow faz o cálculo do gradiente e propaga as correções para as variáveis do modelo embeddings, W e b.
loss = tf.reduce_mean(sampled_loss)
print(loss, '\n')
print(loss.eval())
Tensor("Mean:0", shape=(), dtype=float32)
1.70326
Limpeza das variáveis usadas nessa construção.
session.close()
del X, y, embeddings, X_embed, W, b, sampled_loss, loss
del graph, session
Grafo do Modelo:
Os tensores de entrada X e y são substituídos por placeholder que são fornecidos no momento da execução. O tamanho do lote (batch_size) é substituído por None, indicando uma dimensão não pré-definida, conhecida durante a execução. Por fim, os valores gerados usando NumPy são substituídos pelos equivalentes do TensorFlow (tornando a representação serializada do grafo independente do Python).
A normalização de
embeddingsé discutida no tópico de Nearest Neighbors.
def model_skip_gram(vocabulary_size, embedding_size, num_sampled):
X = tf.placeholder_with_default([0], shape=(None,), name='X')
y = tf.placeholder_with_default([[0]], shape=(None, 1), name='y')
embeddings = tf.Variable(
tf.random_uniform(shape=(vocabulary_size, embedding_size),
minval=-1.0, maxval=1.0),
name='embeddings')
X_embed = tf.nn.embedding_lookup(embeddings, X)
softmax_weights = tf.Variable(
tf.truncated_normal(shape=(vocabulary_size, embedding_size),
stddev=1.0 / np.sqrt(embedding_size)),
name='W')
softmax_biases = tf.Variable(
tf.zeros(shape=(vocabulary_size,)),
name='b')
with tf.name_scope('loss'):
sampled_loss = tf.nn.sampled_softmax_loss(weights=softmax_weights,
biases=softmax_biases,
inputs=X_embed,
labels=y,
num_sampled=num_sampled,
num_classes=vocabulary_size)
loss = tf.reduce_mean(sampled_loss, name='mean')
norm = tf.norm(embeddings, axis=1, keep_dims=True)
normalized_embeddings = embeddings / norm
return X, y, normalized_embeddings, loss
Exemplo:
batch_size = 4
vocabulary_size = 20
embedding_size = 3
num_sampled = 2
with tf.Graph().as_default() as graph, \
tf.Session(graph=graph) as session:
X, y, embeddings, loss_op = model_skip_gram(vocabulary_size,
embedding_size,
num_sampled)
tf.global_variables_initializer().run()
X_batch = np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size,),
dtype=np.int32)
y_batch = np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size, 1),
dtype=np.int32)
feed_data = {X: X_batch, y: y_batch}
loss, embeddings_ = session.run([loss_op, embeddings], feed_dict=feed_data)
print('Avarage loss: {:,.3f}\n'.format(loss))
print(embeddings_)
Avarage loss: 0.816
[[ 0.66777831 0.42373851 0.61197853]
[-0.6535489 -0.74716532 -0.12090418]
[-0.37592143 -0.57527542 -0.72645807]
[-0.51221186 0.10483427 0.8524369 ]
[-0.62320483 -0.65413588 -0.42862791]
[-0.3327882 -0.21835651 -0.91737252]
[-0.19964956 -0.97190893 -0.1246318 ]
[ 0.55537635 0.69427961 0.45774761]
[ 0.8223483 -0.28382188 -0.49314147]
[-0.67327464 -0.50988513 -0.53546101]
[-0.87325156 0.47416174 -0.11226189]
[ 0.71159536 0.57363528 -0.405678 ]
[ 0.74209213 0.55985403 0.36859554]
[ 0.76320887 -0.39777815 -0.50920004]
[-0.86580479 0.33989134 -0.36722746]
[ 0.61622941 -0.1954709 -0.76292366]
[ 0.33821476 -0.42883891 0.83768004]
[ 0.9060387 -0.38017806 -0.18589912]
[ 0.37309805 -0.01781875 0.92762083]
[ 0.52133387 0.68786925 -0.50502163]]
…
Ao final do procedimento descrito nesse tópico, 2 resultados são produzidos:
input_skip_gram(data: List[int], batch_size: int, window_size: int, num_skips: int) -> Iterable[Tuple[ndarray, ndarray]]- função que percorre os dados criando lotes (batches) de entrada e saída esperada (essa função é um generator)model_skip_gram(vocabulary_size: int, embedding_size: int, num_sampled: int) -> Tuple[Tensor, Tensor, Tensor, Tensor]- função que define o fluxo de transformações dos dados para cálculo do erro de predição usada no aprendizado da representação vetorial com TensorFlow
Na sequencia, o código necessário para consulta de palavras similares usando a representação vetorial é desenvolvido.
Nearest Neighbors
A representação vetorial aprendida com Word2vec possui características da linguagem usada no texto. Palavras com significado similar tem vetores próximos e operações aritméticas formam expressões que fazem sentido. A proposta nesse trabalho é usar essa representação para consultar palavras similares.
A similaridade é medida usando o Cosseno.
Essa similaridade varia somente com o ângulo formado entre os vetores, baseado nisso, é possível simplificar o cálculo normalizando os vetores das palavras.
O cálculo das palavras mais próximas (Nearest Neighbors) consiste em calcular a similaridade entre uma palavra e todas as demais e listar as $k$ com maior valor de similaridade.
Formalizando:
Seja $v_i$ e $v_j$ os vetores de duas palavras, então o valor da similaridade é (escalar):
$$ s(v_i, v_j) = \frac{v_i \cdot v_j}{{\lVert v_i \rVert}_2 {\lVert v_j \rVert}_2} $$
Com a normalização:
$$
u_k = \frac{v_k}{\lVert v_k \rVert}_2, \\
k \in [0, \text{vocabulary_size})
$$
Então:
$$
{\lVert u_k \rVert}_2 = 1 \\
s(u_i, u_j) = u_i \cdot u_j
$$
Com $u_i$ o vetor (linha) da palavra inicial e $U$ a matriz dos vetores das palavras (um vetor por linha), então:
$$
S = u_i U'
$$
Onde $S$ é um vetor linha com o valor da similaridade $S_j = u_i \cdot u_j$.
Os índices dos $k$ maiores valores em $S$ correspondem os identificadores das palavras mais similares a $u_i$.
…
O cálculo da normalização da representação vetorial está na função do modelo apresentada nos tópicos anteriores. No desenvolvimento a seguir, os passos para a normalização são mostrados para descrever o funcionamento.
Construção do modelo:
Objetos do TensorFlow necessários para construção e execução do grafo.
tf.InteractiveSession assume a função geral de execução, facilitando evolução incremental.
graph = tf.Graph()
graph.as_default()
session = tf.InteractiveSession(graph=graph)
v_i são vetores de palavras com dimensões (1, 2) e norma 5, que formam ângulos diferentes entre si. V é a matriz com uma linha para cada vetor de palavra, dimensões (4, 2).
v_0 = tf.constant([3, 4], dtype=tf.float32)
v_1 = tf.constant([4, 3], dtype=tf.float32)
v_2 = tf.constant([-3, 4], dtype=tf.float32)
v_3 = tf.constant([-4, 3], dtype=tf.float32)
V = tf.stack([v_0, v_1, v_2, v_3])
print(V, '\n')
print(V.eval())
Tensor("stack:0", shape=(4, 2), dtype=float32)
[[ 3. 4.]
[ 4. 3.]
[-3. 4.]
[-4. 3.]]
Cálculo da norma de v_i usando a função tf.norm.
V_norm = tf.norm(V, axis=1, keep_dims=True)
print(V_norm, '\n')
print(V_norm.eval())
Tensor("norm/Sqrt:0", shape=(4, 1), dtype=float32)
[[ 5.]
[ 5.]
[ 5.]
[ 5.]]
U tem os mesmos vetores de V, com norma 1.
U = V / V_norm
print(U, '\n')
print(U.eval())
Tensor("truediv:0", shape=(4, 2), dtype=float32)
[[ 0.60000002 0.80000001]
[ 0.80000001 0.60000002]
[-0.60000002 0.80000001]
[-0.80000001 0.60000002]]
O código a seguir é uma ‘inspeção’ da normalização, não faz parte do modelo.
UU é o vetor do produto dos vetores normalizados das palavras $ \text{UU}_i = u_i \cdot u_i $ (todos os valores devem ser igual a 1).
UU = tf.diag_part(tf.matmul(U, U, transpose_b=True))
print(UU, '\n')
print(UU.eval())
Tensor("DiagPart:0", shape=(4,), dtype=float32)
[ 1. 1. 1. 1.]
i é o identificador (índice) da palavra inicial, correspondendo ao vetor u_i.
i = tf.constant([0], dtype=tf.int32)
u_i = tf.nn.embedding_lookup(U, i)
print(u_i, '\n')
print(u_i.eval())
Tensor("embedding_lookup:0", shape=(1, 2), dtype=float32)
[[ 0.60000002 0.80000001]]
S é o vetor com o valor da similaridade de u_i com todos os outros vetores de palavras.
S = tf.matmul(u_i, U, transpose_b=True)
print(S, '\n')
print(S.eval())
Tensor("MatMul:0", shape=(1, 4), dtype=float32)
[[ 1.00000000e+00 9.60000038e-01 2.80000001e-01 7.15255766e-09]]
A tupla (nn_values, nn_indices) corresponde ao valor da similaridade e ao índice dos vetores (igual ao identificador) de maior similaridade.
Todo vetor tem similaridade 1 com si mesmo e pode ter similaridade 1 com outros vetores. Na prática, para termos pelo menos
$k$índices diferentes, é necessário uma lista de$k+1$índices. Duas condições devem ser tratadas: a lista conter ou não o próprio vetor. No primeiro caso, o próprio vetor é descartado e no segundo, qualquer vetor pode ser descartado (para não conter o próprio vetor, é necessário$k+1$outros vetores com similaridade 1).
nn_values, nn_indices = tf.nn.top_k(S, 2)
print(nn_values, '\n')
print(nn_values.eval(), '\n')
print(nn_indices, '\n')
print(nn_indices.eval())
Tensor("TopKV2:0", shape=(1, 2), dtype=float32)
[[ 1. 0.96000004]]
Tensor("TopKV2:1", shape=(1, 2), dtype=int32)
[[0 1]]
Limpeza das variáveis usadas nessa construção.
session.close()
del v_0, v_1, v_2, v_3, V, V_norm, U
del i, u_i, S, nn_values, nn_indices
del graph, session
Código:
class NearestWordsQuery:
def __init__(self, word_from_id, words, k=4):
self.word_from_id = word_from_id
self.words = words
self.k = k
def build_graph(self, embeddings, name=None):
with tf.name_scope(name, "nearest_words", [self.words, self.k]):
input_words = tf.placeholder(tf.int32, shape=(None,))
input_embed = tf.nn.embedding_lookup(embeddings, input_words)
similarity = tf.matmul(input_embed, embeddings, transpose_b=True)
nearest = tf.nn.top_k(similarity, self.k+1)
self.input_words = {input_words: self.words}
self.nearest = nearest
def nearest_words(self, target_id, nearest_indices, nearest_values):
id_pairs = zip(nearest_indices, nearest_values)
word_pairs = list((self.word_from_id[word_id], value)
for word_id, value in id_pairs
if word_id != target_id)
return word_pairs[:self.k]
def format_words(self, word_pairs):
return ('{} ({:,.3f})'.format(word, value)
for word, value in word_pairs)
def run(self, session):
nearest_val, nearest_id = session.run(self.nearest,
feed_dict=self.input_words)
for i, word_id in enumerate(self.words):
word = self.word_from_id[word_id]
nearest_words = self.nearest_words(
word_id, nearest_id[i], nearest_val[i])
nearest_words = ', '.join(self.format_words(nearest_words))
print('{}: {}'.format(word, nearest_words))
Exemplo:
rev_vocab = {0: 'unk', 1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
vocabulary_size = len(rev_vocab)
embedding_size = 3
nn = NearestWordsQuery(rev_vocab, words=[2, 5], k=2)
with tf.Graph().as_default() as graph, \
tf.Session(graph=graph) as session:
V = 2 * np.random.rand(vocabulary_size, embedding_size) - 1
U = V / np.linalg.norm(V, axis=1, keepdims=True)
embeddings = tf.constant(U)
nn.build_graph(embeddings)
nn.run(session)
b: a (0.788), d (0.545)
e: c (0.620), a (0.345)
…
Ao final do procedimento descrito nesse tópico, 1 resultado é produzido:
NearestWordsQuery(word_from_id: Dict[int, str], words: List[int], k:int)- classe que lista palavras similares às palavras emwordsusando similaridade por Cosseno.
Na sequencia, são mostrados os experimentos com ambos os modelos do Word2vec e a aplicação de palavras similares.
Experimentos
O treinamento consiste em construir um grafo de operações que calcula uma função objetivo a partir dos dados e usar um algoritmo de otimização que minimiza essa função objetivo usando o gradiente. O TensorFlow permite construir esse grafo como operações sobre tensores e oferece vários algoritmos de otimização, juntamente com ferramentas para facilitar a execução e visualização desse processo.
Mais sobre funcionalidades de treinamento com TensorFlow aqui.
No caso do Word2vec, a função objetivo é o erro de predição de palavras modelada como uma classificação Softmax sobre todas as palavras possíveis (classes). Para diminuir o custo computacional dessa função objetivo, é usada amostra das classes para calcular o erro aproximado.
O algoritmo de otimização usado é o Adagrad. Os resultados mostram que tem um bom custo-benefício nos modelos do NLP, Word2vec em particular.
Para adicionar o algoritmo ao grafo, o TensorFlow oferece a função tf.contrib.layers.optimize_loss que tem monitoramento do valor do erro e outras customizações.
O TensorFlow define a instância de execução de um grafo com o objeto tf.Session. Para o treinamento, é recomendado usar o tf.train.MonitoredTrainingSession que oferece serviços adicionais como tf.train.CheckpointSaverHook que salva o modelo em uma pasta e tf.train.SummarySaverHook que salva valores monitorados da execução. Os arquivos gerados por essas extensões podem ser visualizados com o TensorBoard.
Código da função que adiciona o algoritmo de otimização:
def opt_adagrad(loss, learning_rate=1.0):
return tf.contrib.layers.optimize_loss(
loss=loss,
global_step=tf.train.get_or_create_global_step(),
learning_rate=learning_rate,
optimizer='Adagrad')
Código da função que executa o treinamento:
def train(model_fn, input_fn, opt_fn, query,
num_epochs=1, model_dir='/tmp/embedding_model', remove_model=True):
if remove_model and os.path.isdir(model_dir):
shutil.rmtree(model_dir)
with tf.Graph().as_default():
X, y, embeddings, loss_op = model_fn()
train_op = opt_fn(loss_op)
query.build_graph(embeddings)
with tf.train.MonitoredTrainingSession(
checkpoint_dir=model_dir) as session:
for epoch in range(1, num_epochs+1):
print('Epoch {}\n'.format(epoch))
avg_loss = 0
for step, (X_batch, y_batch) in enumerate(input_fn()):
_, loss = session.run([train_op, loss_op],
feed_dict={X: X_batch, y: y_batch})
avg_loss = (loss + step * avg_loss) / (step + 1)
if step % 10_000 == 0:
print('...{:,d} Avarage loss: {:.3f}'.format(
step, avg_loss))
print('\nAvarage loss: {:.3f}\n'.format(avg_loss))
query.run(session)
print()
return session.run(embeddings)
Função para salvar em arquivo a representação vetorial aprendida no treinamento:
def save_embeddings(file, embeddings):
with open(file, 'w') as f:
vocabulary_size = embeddings.shape[0]
for word_id in range(vocabulary_size):
embedding = embeddings[word_id]
embedding_string = ('{:.5f}'.format(k) for k in embedding)
embedding_string = ' '.join(embedding_string)
f.write(embedding_string)
f.write('\n')
Na sequencia, essas funções são usadas no aprendizado da representação vetorial das palavras com os dois modelos do Word2vec.
…
Treinamento
Para se ter uma ‘percepção qualitativa’ do resultado, são amostradas 8 palavras do intervalo das 1000 mais comuns - no final de cada época, essa amostra é usada para gerar a lista de similaridade. Essa lista pode ser observada para ver como o aprendizado evolui.
Essa é uma amostra aleatória e vai ser diferente a acada execução.
valid_num_words = 8
valid_range_words = 1000
valid_words = random.sample(range(1, valid_range_words), valid_num_words)
for word_id in valid_words:
print(word_from_id[word_id])
each
length
writer
great
go
literature
seven
examples
A amostra de palavras é encapsulada no objeto que consulta palavras similares a partir da representação vetorial.
nearest_words = NearestWordsQuery(word_from_id, valid_words, 4)
Essa amostra é usada em ambos os treinamentos para comparação.
Treinamento do CBOW:
%%timeé uma diretiva do Jupyter para medir o tempo de execução de uma célula - caso a execução desse código não seja no Jupyter, é necessário remover essa linha.
%%time
MODEL_DIR = os.path.join('word2vec', 'cbow')
EMBEDDINGS_FILE = os.path.join('word2vec', 'cbow.txt')
vocabulary_size = len(word_to_id)
embedding_size = 128
num_sampled = 64
batch_size = 128
window_size = 3
model_fn = lambda: model_cbow(vocabulary_size, embedding_size, num_sampled)
input_fn = lambda: input_cbow(data, batch_size, window_size)
opt_fn = lambda loss: opt_adagrad(loss, learning_rate=1.0)
cbow_embeddings = train(model_fn,
input_fn,
opt_fn,
nearest_words,
num_epochs=1,
model_dir=MODEL_DIR)
save_embeddings(EMBEDDINGS_FILE, cbow_embeddings)
Epoch 1
...0 Avarage loss: 7.609
...10,000 Avarage loss: 3.445
...20,000 Avarage loss: 3.273
...30,000 Avarage loss: 3.186
...40,000 Avarage loss: 3.118
...50,000 Avarage loss: 3.076
...60,000 Avarage loss: 3.035
...70,000 Avarage loss: 2.999
...80,000 Avarage loss: 2.969
...90,000 Avarage loss: 2.944
...100,000 Avarage loss: 2.916
...110,000 Avarage loss: 2.886
...120,000 Avarage loss: 2.869
...130,000 Avarage loss: 2.847
Avarage loss: 2.844
each: every (0.632), any (0.551), all (0.357), incitement (0.327)
length: variation (0.377), maximum (0.375), halting (0.363), speed (0.360)
writer: author (0.525), politician (0.521), mathematician (0.519), poet (0.511)
great: little (0.422), dearborn (0.397), soi (0.373), considerable (0.365)
go: went (0.380), move (0.362), pass (0.358), preventative (0.351)
literature: texts (0.400), beaverbrook (0.357), markup (0.344), playwright (0.340)
seven: eight (0.869), five (0.833), six (0.832), four (0.826)
examples: aspects (0.431), elements (0.409), anise (0.376), cases (0.351)
CPU times: user 13min 27s, sys: 30.3 s, total: 13min 57s
Wall time: 8min 51s
Treinamento do Skip-gram:
%%timeé uma diretiva do Jupyter para medir o tempo de execução de uma célula - caso a execução desse código não seja no Jupyter, é necessário remover essa linha.
%%time
MODEL_DIR = os.path.join('word2vec', 'skip_gram')
EMBEDDINGS_FILE = os.path.join('word2vec', 'skip_gram.txt')
vocabulary_size = len(word_to_id)
embedding_size = 128
num_sampled = 64
batch_size = 128
window_size = 3
num_skips = 2
model_fn = lambda: model_skip_gram(vocabulary_size, embedding_size, num_sampled)
input_fn = lambda: input_skip_gram(data, batch_size, window_size, num_skips)
opt_fn = lambda loss: opt_adagrad(loss, learning_rate=1.0)
skip_embeddings = train(model_fn,
input_fn,
opt_fn,
nearest_words,
num_epochs=1,
model_dir=MODEL_DIR)
save_embeddings(EMBEDDINGS_FILE, skip_embeddings)
Epoch 1
...0 Avarage loss: 8.529
...10,000 Avarage loss: 3.854
...20,000 Avarage loss: 3.685
...30,000 Avarage loss: 3.615
...40,000 Avarage loss: 3.570
...50,000 Avarage loss: 3.541
...60,000 Avarage loss: 3.517
...70,000 Avarage loss: 3.490
...80,000 Avarage loss: 3.472
...90,000 Avarage loss: 3.462
...100,000 Avarage loss: 3.449
...110,000 Avarage loss: 3.436
...120,000 Avarage loss: 3.423
...130,000 Avarage loss: 3.414
...140,000 Avarage loss: 3.401
...150,000 Avarage loss: 3.390
...160,000 Avarage loss: 3.383
...170,000 Avarage loss: 3.376
...180,000 Avarage loss: 3.369
...190,000 Avarage loss: 3.362
...200,000 Avarage loss: 3.351
...210,000 Avarage loss: 3.336
...220,000 Avarage loss: 3.332
...230,000 Avarage loss: 3.325
...240,000 Avarage loss: 3.322
...250,000 Avarage loss: 3.312
...260,000 Avarage loss: 3.307
Avarage loss: 3.306
each: every (0.658), any (0.554), all (0.441), several (0.371)
length: size (0.406), amount (0.394), cost (0.385), omphalos (0.339)
writer: author (0.661), poet (0.571), physicist (0.519), actor (0.509)
great: considerable (0.529), huge (0.456), significant (0.424), little (0.416)
go: went (0.543), get (0.478), pass (0.446), put (0.434)
literature: poetry (0.506), philosophy (0.441), art (0.410), mathematics (0.371)
seven: five (0.845), eight (0.825), four (0.819), six (0.799)
examples: forms (0.422), aspects (0.397), types (0.370), definitions (0.363)
CPU times: user 21min 27s, sys: 56.2 s, total: 22min 23s
Wall time: 14min 7s
Em ambos os modelos, os resultados são interessantes, como a palavra writer próxima de author e poet e a palavra seven próxima de five e eight. O erro médio é decrescente que é o esperado (contudo, não é possível avaliar). Existe uma diferença significativa entre os tempos de execução, mas isso ocorre porque em ambos os casos, o treinamento é feito para uma época completa e a época do Skip-gram tem o dobro de exemplos da época do CBOW (o primeiro tem num_windows * num_skips e o segundo só num_windows, onde num_windows é igual e num_skips é 2).
Na prática, seria necessário definir métricas qualitativas mensuráveis e um plano de treinamento mais elaborado para orientar o tuning dos parâmetros do modelo (como o embedding_size), fazer análise de overfitting e introduzir regularização. Esse é o trabalho mais importante da aplicação de Machine Learning em uma tarefa real, contudo, vai além da proposta desse trabalho (implementação do modelo com TensorFlow). Para o uso real do Word2vec, é necessário tratar essa ‘omissão’.
Na sequencia, a visualização de resultados usando TensorBoard.
…
TensorBoard
TensorBoard é uma aplicação Web com múltiplas funcionalidades de visualização sobre artefatos gerados com TensorFlow. Nesse trabalho, temos três funcionalidades em particular que são exploradas: visualização do erro, do grafo e da representação vetorial.
Para o TensorBoard funcionar, é necessário adicionar as operações de monitoramento no grafo (Summary) e salvar em um pasta o resultado da execução dessas operações (de tempos em tempos).
Durante o treinamento, o objeto MonitoredTrainingSession já faz o trabalho de agregar todas as operações de monitoramento e salvar junto com o checkpoint das variáveis do modelo. O intervalo é configurável e por default ocorre a cada 100 passos (definido pela variável do grafo global_step).
Ao usar a função tf.contrib.layers.optimize_loss, já é adicionado o monitoramento do valor escalar do erro (OptimizeLoss/loss) que pode ser visualizado no TensorBoard.
Ao salvar os resultados do monitoramento, a visualização do grafo também fica disponível no TensorBoard.
Com o checkpoint do modelo e os metadados do grafo, é possível usar a visualização de embeddings do TensorBoard usando redução de dimensão com PCA ou t-SNE.
Para usar o TensorBoard é necessário executar o servidor no console e acessar pelo navegador:
O TensorBoard é instalado pelo pacote do TensorFlow. O executável fica na pasta em que o Python define a instalação de binários.
$ tensorboard --logdir=word2vec
Abrir o navegador no endereço:
Página do TensorBoard:
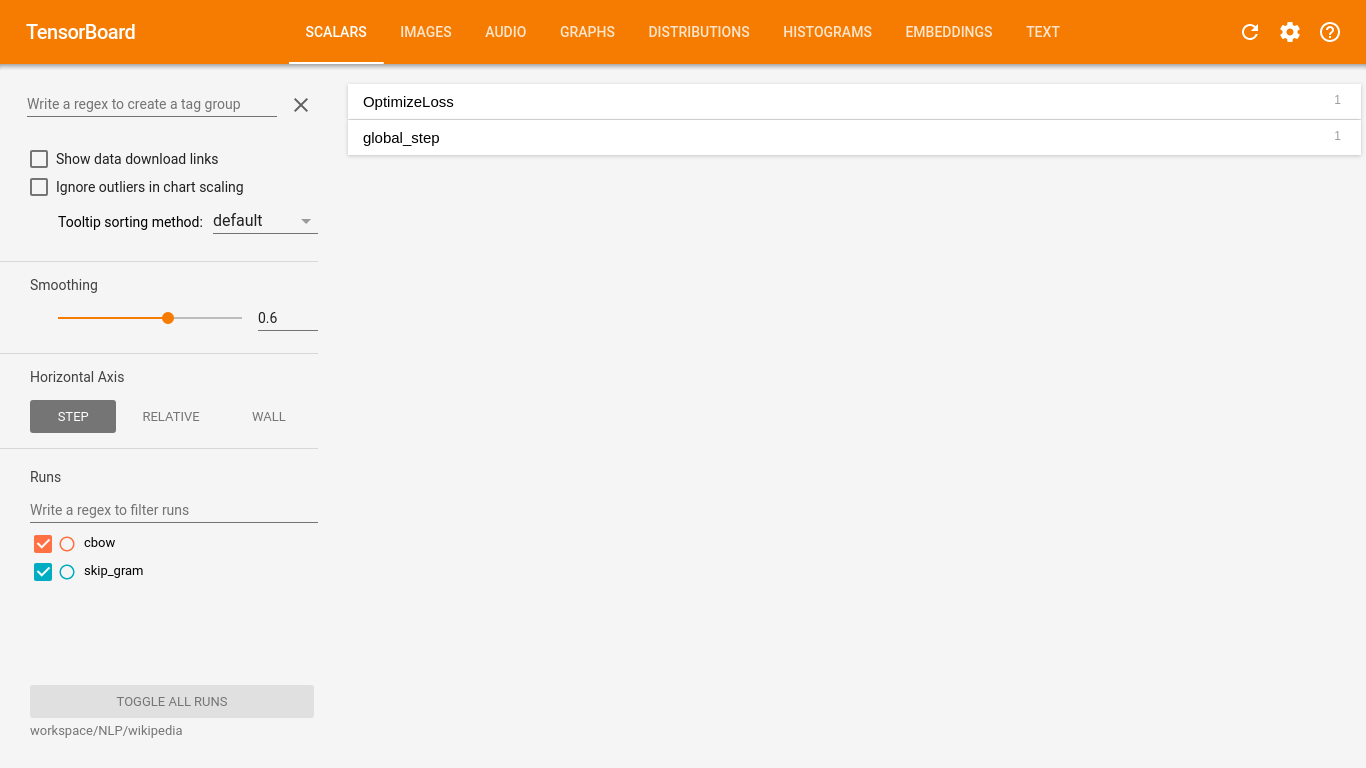
A página inicial é para visualização de valores escalares. Em ambos os treinamentos, o valor escalar é a medida do erro e pode ser acessada no retângulo com a denominação OptimizeLoss. No lado esquerdo, parte inferior, tem a lista de treinamentos salvos e a correspondência entre as cores dos gráficos. Apenas os valores dos treinamentos selecionados são exibidos.
Segue a imagem capturada do gráfico da medida de erro selecionando-se um treinamento por vez.
Medida do Erro no treinamento do CBOW:
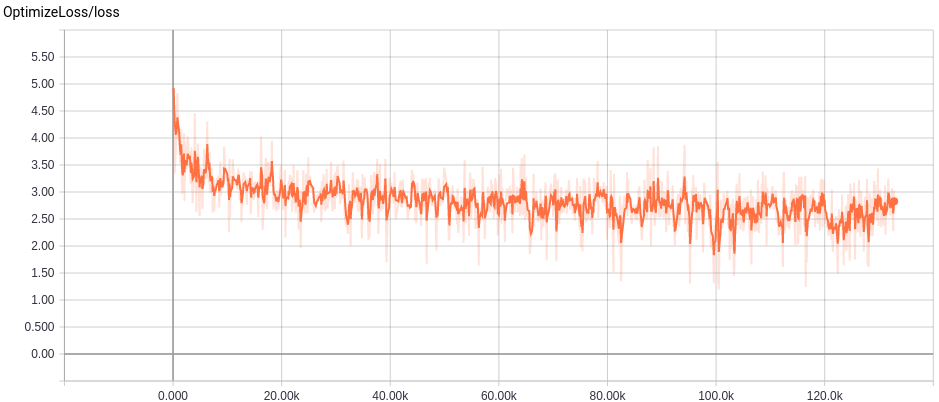
Medida do Erro no treinamento do Skip-Gram:
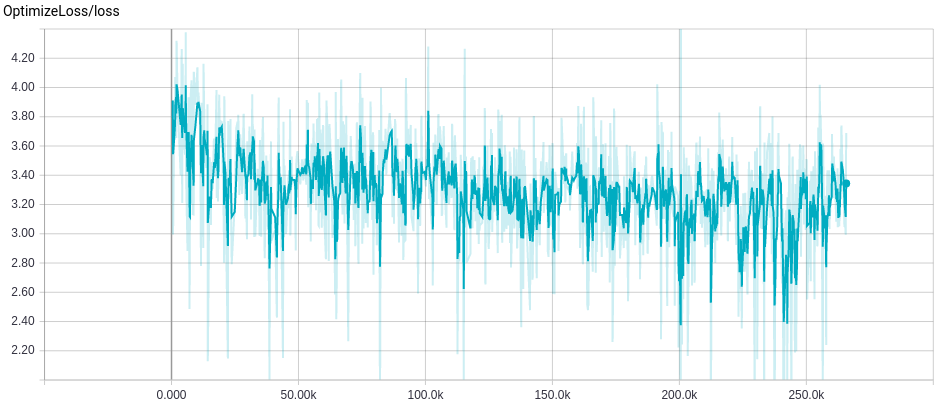
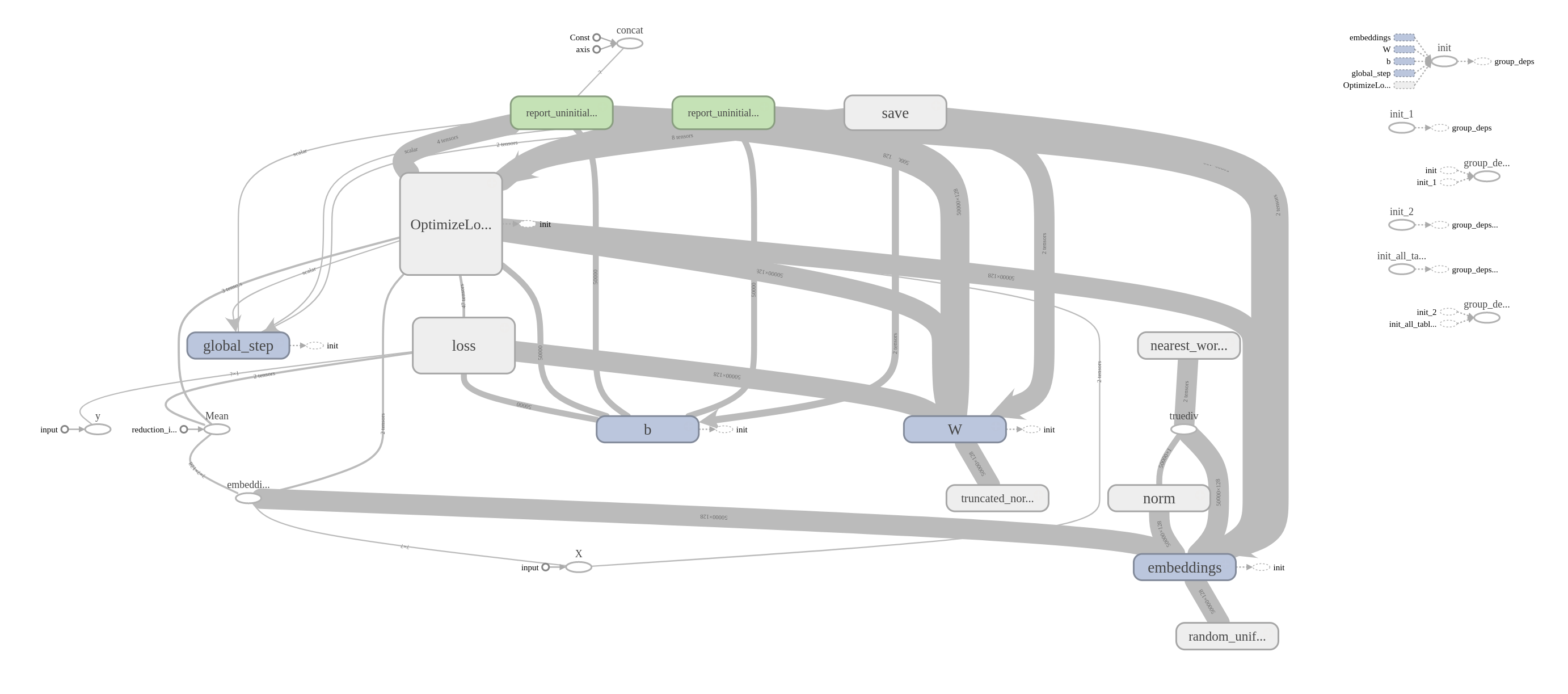
No menu superior, selecionando-se a opção GRAPHS é possível visualizar a representação visual do modelo de treinamento. No lado esquerdo, parte superior tem um seletor Run para escolher qual grafo visualizar. Essa visualização é interativa, permitindo visualizar parâmetros, fazer zoom, visualizar dentro dos blocos; vale a pena explorar.
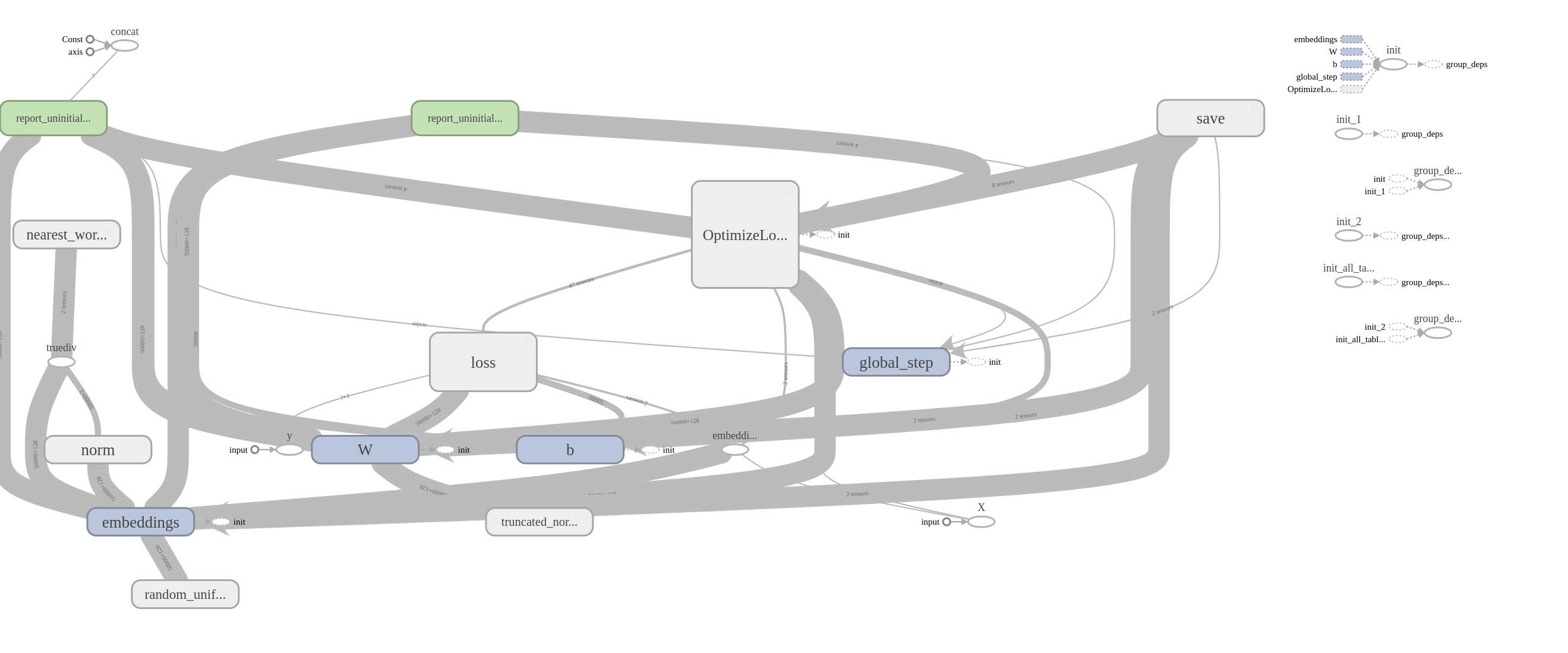
Segue a imagem gerada pelo comando Download PNG selecionando-se um treinamento por vez.
Grafo do treinamento do CBOW:
Grafo do treinamento do Skip-Gram:
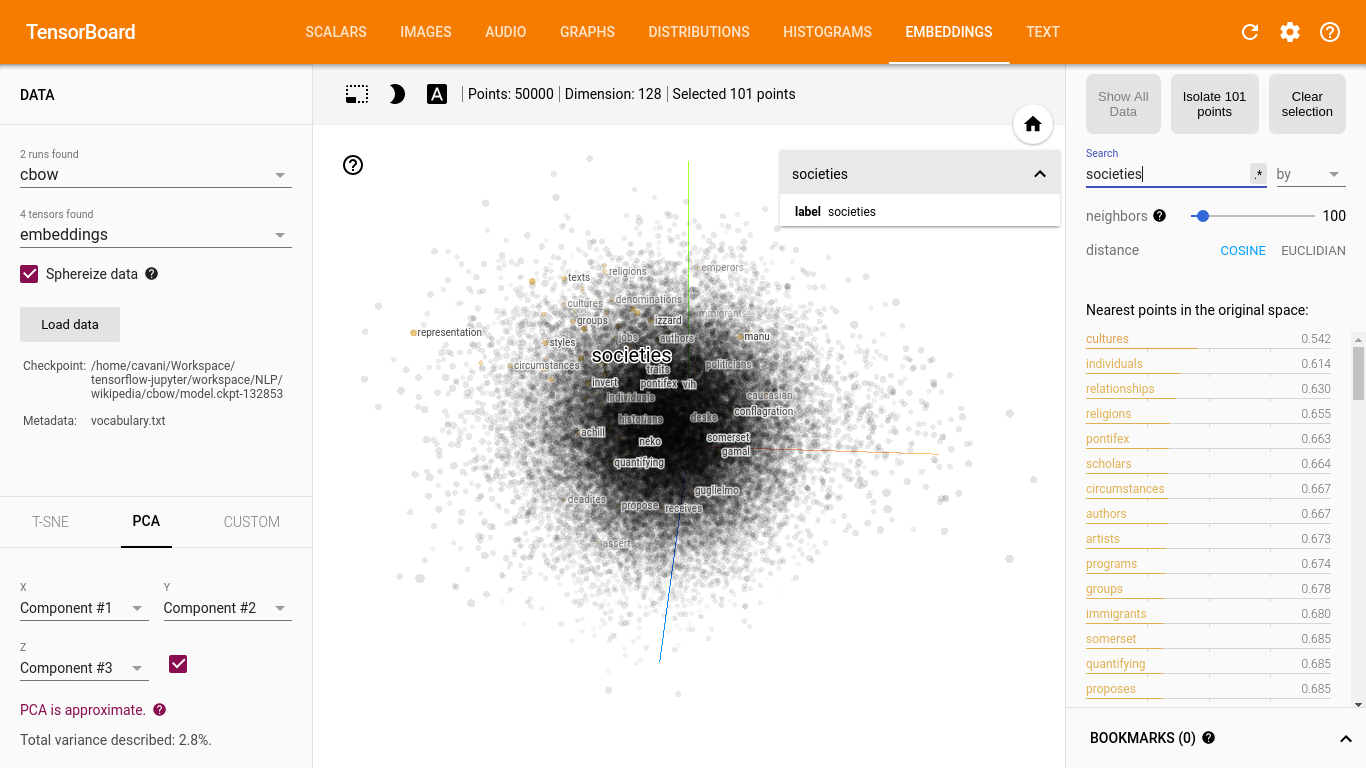
No menu superior, selecionando-se a opção EMBEDDINGS é possível visualizar a representação vetorial aprendida pelo modelo. No lado esquerdo, parte superior tem dois seletores, o primeiro permite a escolha do treinamento e o segundo a escolha do tensor a ser visualizado. Abaixo dos seletores, tem o comando Load data que pode ser usado para carregar o aquivo vocabulary.txt gerado na Preparação dos Dados. Essa visualização é interativa, permitindo visualizar as palavras mais próximas, separar uma região, fazer zoom; vale a pena explorar.
A primeira imagem é a captura da tela com a seleção do treinamento do CBOW e do tensor embeddings, com o carregamento dos dados do arquivo vocabulary.txt e buscando a palavra societies no seletor da direita, parte superior.
A segunda imagem é a mesma configuração com o treinamento do Skip-gram.
Visualização da representação vetorial do CBOW:
Visualização da representação vetorial do Skip-gram:
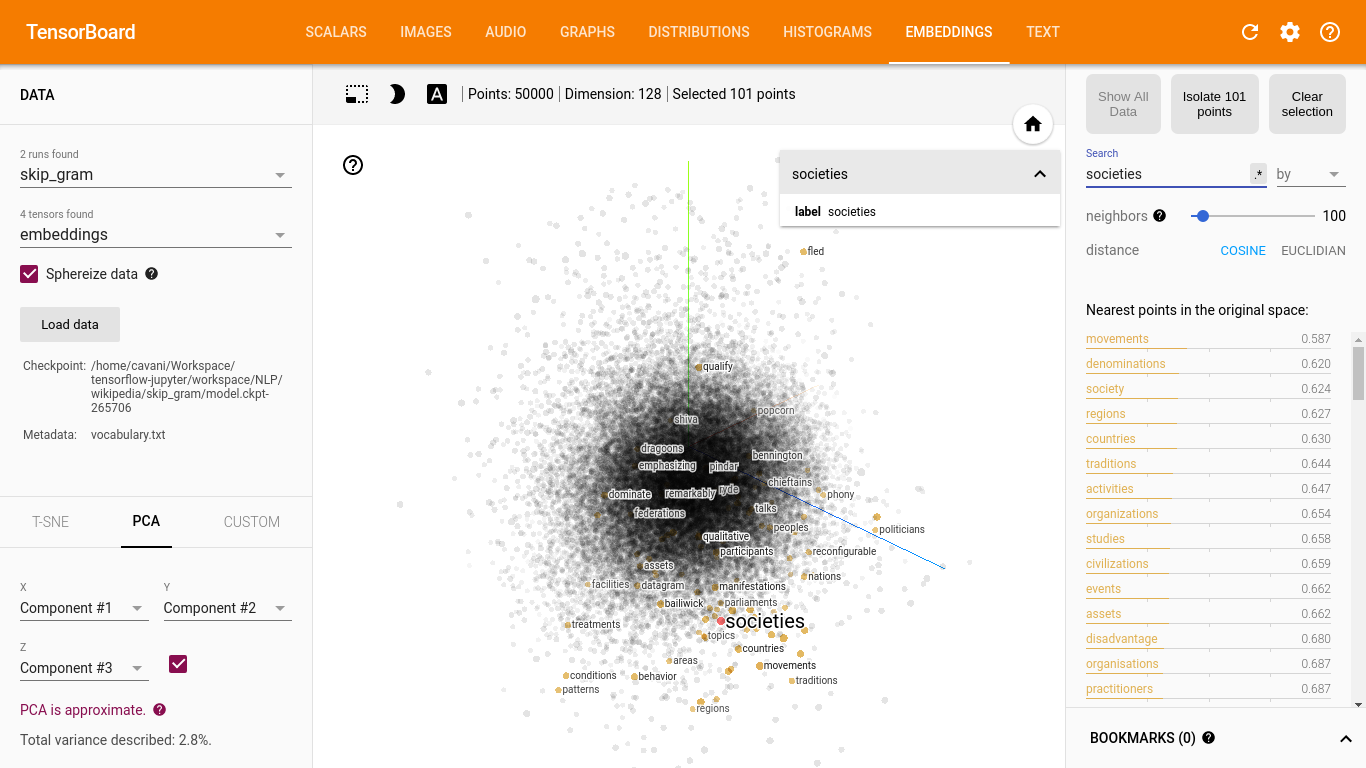
…
Ao final do procedimento descrito nesse tópico, 2 resultados são produzidos:
word2vec/{cbow.txt,skip_gram.txt}` - um arquivo por modelo com a representação vetorial das palavras (formato texto de fácil leitura independente de linguagem ou framework)word2vec/{cbow,skip_gram}- uma pasta por modelo do checkpoint com os resultados do treinamento, podem ser usados para análises e novas iterações do treinamento
Esse é o resultado final desse trabalho.
Conclusão
A representação vetorial de palavras é um tema importante em NLP e é bastante utilizado nas técnicas de Deep Learning aplicadas nessa área. Nesse trabalho, foi mostrada a implementação de um dos modelos mais populares, o Word2vec. Uma das características mais interessantes desse modelo é que a posição relativa dos vetores no espaço absorve relações semânticas de palavras e isso é obtido por aprendizado, sem regras pré-fixadas.
Como foi mostrado, vetores como writer, author e poet são similares na representação vetorial aprendida. Não foi necessário especificar uma regra para declarar essa relação.
Outro modelo similar ao Word2vec é o GloVe que usa estatísticas do texto (frequência das palavras, co-ocorrência) para melhorar a representação vetorial. Esse projeto disponibiliza a representação vetorial de um extenso vocabulário de palavras, aprendida com treinamento em um vasto conteúdo.
A proposta desse trabalho foi fazer a implementação com TensorFlow. TensorFlow é um framework de computação numérica que facilita o desenvolvimento de aplicações de Machine Learning. Incluindo ferramental como TensorBoard que facilita a visualização e análise de modelos.
Como foi mostrado, o TensorFlow foi usado na construção do grafo de operações que calcula a função objetivo do Word2vec a partir de transformação de texto em linguagem natual; esse grafo foi otimizado usando Adagrad, um algoritmo que usa o gradiente e tem boa performance com modelos de NLP. O TensorBoard foi usado para visualização da minimização do erro no treinamento e a exploração da representação vetorial.
Dois assuntos foram omitidos nesse trabalho: um plano de treinamento mais elaborado para uso do Word2vec na prática e uma solução integrada para treinar e servir o modelo. No primeiro caso, o paper tem uma boa discussão sobre o assunto. No segundo caso, o TensorFlow oferece o TensorFlow Serving para esse propósito; a ideia é abordar esse assunto no futuro.
Uma limitação desse trabalho é que, a princípio, a representação vetorial de palavras é ‘limitada à palavra’ sendo necessário algo mais para trabalhar com texto.
No interesse de aprender algoritmos que sejam capazes de interpretar e compreender texto em linguagem natural, a ideia é explorar esse algo mais. Nos próximos artigos, a proposta é mostrar como estender o Word2vec para representação de texto (Paragraph2vec) e passar para outros modelos que usam representação vetorial com arquiteturas como LSTM, Memory Networks e Seq2seq. As técnicas mais interessantes de Deep Learning para NLP.
Referências
Word Embedding (Wikipedia)
Word2vec (Wikipedia)
Efficient Estimation of Word Representations in Vector Space (Word2vec paper)
Vector Representations of Words (Tutorial do próprio TensorFlow)
Udacity Deep Learning Course (Lesson 5: Deep Models for Text and Sequences)
Stanford CS224n: Natural Language Processing with Deep Learning
Lecture 2 - Word Vector Representations: word2vec [ YouTube ] [ Slides (PDF) ]Chris McCormick’s Tutorial: