Esse artigo é sobre a implementação do Paragraph2vec no TensorFlow. Paragraph2vec é um par de modelos de aprendizado não supervisionado para criação de uma representação vetorial de documentos com texto em linguagem natural. O Paragraph2vec é similar ao Word2vec usado para representação de palavras, e também apresenta características semânticas. Nesse artigo, o Paragraph2vec é usado em uma aplicação de análise de sentimento que classifica comentários do Rotten Tomatoes como positivo ou negativo.
Código
Para executar o Notebook:
Linux (ou Mac), executar no terminal os comandos abaixo. O último comando inicia o servidor do Jupyter que fica executando (Ctrl-C para terminar). Ele abre automaticamente um navegador com a lista de arquivos do projeto. Para acessar o notebook, entre na pasta
NLPe abra o arquivoParagraph2vec.ipynb.$ git clone https://github.com/cirocavani/tensorflow-jupyter.git $ cd tensorflow-jupyter $ ./setup.sh $ bin/jupyter-notebook
O código mostrado nesse artigo é autocontido, ou seja, pode ser executado passo a passo (necessário Python3 e TensorFlow). Essa é uma versão simplificada do código disponível no Notebook.
Esse código foi testado na versão 1.2.1 do TensorFlow.
…
Motivação
No artigo do Word2vec, uma das limitações identificadas foi que a representação vetorial de palavras não é diretamente aplicável para compreensão de texto como um todo. O Paragraph2vec foi desenvolvido como uma forma de tratar essa limitação, mantendo o processo não supervisionado de aprendizado e as características semânticas dos vetores.
O Paragraph2vec é um modelo que pode ser usado para criação de uma representação vetorial de documentos. Os documentos, texto de diferentes tamanhos e estruturas, são transformados em vetores de tamanho fixo. Esses vetores preservam o significado do texto e podem ser usados como entrada (feature) em modelos que executam tarefas de ‘compreensão’. Nesse sentido, o Paragraph2vec pode ser visto como uma etapa de pré-processamento para tarefas como Análise de Sentimento, Information retrieval ou Recomendação.
Nesse artigo, o objetivo é explorar o par de modelos do Paragraph2vec introduzido no paper Distributed Representations of Sentences and Documents. Em artigos futuros, a ideia é explorar modelos que aprendem a representação vetorial de texto usando LSTM.
Introdução
O Paragraph2vec consiste em dois modelos de aprendizado não supervisionado: o Distributed Memory (DM) e o Distributed Bag-of-Words (DBOW). Em ambos, o aprendizado é feito sobre documentos com texto em linguagem natural. Cada documento é processado através de janela de tamanho fixo que se desloca palavra a palavra. No DM, a representação do documento é combinada com as representações das palavras iniciais para predizer a última palavra da janela. No DBOW a representação do documento é usada diretamente para predizer todas as palavras da janela.
O aprendizado consiste em maximizar a probabilidade do que se está predizendo (última palavra ou todas as palavras da janela) condicionada pela observação da evidência (documento e palavras iniciais ou somente o documento).
A distribuição de probabilidade é calculada usando uma camada única, consistindo de um classificador linear com Softmax para todas as palavras possíveis (classes do classificador). No DM, a entrada pode ser de duas formas: concatenação do vetor do documento com os vetores das palavras iniciais da janela (menos a última), ou; a média desses vetores. No DBOW, a entrada é somente o vetor do documento. A saída é a distribuição de probabilidade sobre todas as palavras possíveis (Softmax). O erro é calculado usando Cross Entropy para a predição da última palavra (DM) ou predição de todas as palavras da janela (DBOW). O erro é usado para ajustar os pesos do classificador e dos vetores dos documentos (no DM, também é usado para corrigir os vetores das palavras).
Dessa forma, os parâmetros a serem aprendidos são: no DM, os vetores dos documentos, vetores das palavras e a matriz (mais bias) que relaciona o vetor de entrada (combinação do vetor do documento e das palavras, concatenação ou média) com as classes de saída (palavras possíveis); no DBOW, os vetores dos documentos e a matriz (mais bias) que relaciona o vetor de entrada (vetor do documento) com as classes de saída (palavras possíveis).
A partir da representação vetorial dos documentos, é usado Logistic Regression para aprender a classificar o documento como tendo sentimento positivo ou negativo. A entrada é o vetor de um dos modelos do Paragraph2vec ou a concatenação de ambos os vetores e a saída é a variável binária indicando positivo ou negativo. Nesse caso, os parâmetros a serem aprendidos são os pesos para cada dimensão do vetor de entrada mais o bias.
Esse artigo mostra como esses três modelos são implementados com TensorFlow.
Esse trabalho é dividido nos tópicos:
-
Transformação do dataset, comentários sobre filmes do Rotten Tomatoes, no formato usado no modelo.
-
Função de entrada de dados e grafo do modelo de aprendizado do primeiro modelo do Paragraph2vec.
Distributed Bag-of-Words (DBOW)
Função de entrada de dados e grafo do modelo de aprendizado do segundo modelo do Paragraph2vec.
-
Aplicação de análise de sentimento que classifica comentários do Rotten Tomatoes como positivo ou negativo usando a representação vetorial.
-
Especificação do treinamento, visualização usando TensorBoard.
-
Considerações sobre a implementação e próximos assuntos.
-
Links do material em que esse trabalho foi baseado.
Módulos necessários para o código presente nesse artigo:
import collections
import os
import random
import requests
import shutil
import zipfile
import tensorflow as tf
import numpy as np
tf.logging.set_verbosity(tf.logging.ERROR)
…
Preparação dos Dados
O treinamento do Paragraph2vec é feito com documentos de texto em linguagem natural. A princípio, esses documentos podem variar de sentenças curtas a textos com múltiplos parágrafos. O desempenho do aprendizado depende da variedade do texto, onde palavras com poucas ocorrências resultam em sinais fracos e palavras dominantes resultam em oversampling. Na prática, apesar do aprendizado ser não supervisionado, é necessário que o dataset seja bem condicionado e que a amostragem do texto seja equilibrada.
Para esse trabalho, o dataset usado é uma amostra de comentários sobre filmes do Rotten Tomatoes. Esse é um dataset pequeno, em que cada comentário é uma sentença curta (poucas palavras) com pontuação, já segmentado (espaço entre os tokens). Esses comentários foram manualmente classificados pelo sentimento do texto com um valor de 0 a 1 (de negativo para positivo). Esse dataset foi escolhido por ser discutido no paper do Paragraph2vec (o paper obteve o estado-da-arte na classificação de sentimento nesse dataset, contudo, reproduzir esse resultado não é o objetivo aqui).
Stanford Sentiment Treebank V1.0
[ Site ] [ stanfordSentimentTreebank.zip ] (~6MB)
This is the dataset of the paper:
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher Manning, Andrew Ng and Christopher Potts
Conference on Empirical Methods in Natural Language Processing (EMNLP 2013)
Semantic word spaces have been very useful but cannot express the meaning of longer phrases in a principled way. Further progress towards understanding compositionality in tasks such as sentiment detection requires richer supervised training and evaluation resources and more powerful models of composition. To remedy this, we introduce a Sentiment Treebank. It includes fine grained sentiment labels for 215,154 phrases in the parse trees of 11,855 sentences and presents new challenges for sentiment compositionality. To address them, we introduce the Recursive Neural Tensor Network. When trained on the new treebank, this model outperforms all previous methods on several metrics. It pushes the state of the art in single sentence positive/negative classification from 80% up to 85.4%. The accuracy of predicting fine-grained sentiment labels for all phrases reaches 80.7%, an improvement of 9.7% over bag of features baselines. Lastly, it is the only model that can accurately capture the effect of contrastive conjunctions as well as negation and its scope at various tree levels for both positive and negative phrases.
O processo consiste em:
- Carregamento dos dados com download e combinação dos arquivos
- Análise para construção do vocabulário e índice de documentos
- Transformação do texto da sequencia de palavras na sequencia de índices do vocabulário e documentos
- Transformação da escala de classificação de sentimento em variável binária, positiva ou negativa
…
Carregamento
O dataset está disponível no site de Stanford e pode ser baixado diretamente. Apenas um subconjunto dos arquivos do dataset é necessário para o treinamento dos modelos. Esses arquivos precisam ser combinados para serem processados primeiro no treinamento da representação vetorial dos documentos (sentenças) e depois no classificador da análise de sentimento.
A primeira listagem de código faz o download e desempacotamento dos arquivos necessários nesse trabalho.
A segunda listagem de código faz a combinação desses arquivos para formação dos dados usados no treinamento.
Os arquivos usados são:
datasetSentences.txt- arquivo texto com duas colunas, a primeira com um índice (começando em 1) e a segunda com o texto de cada sentença; com cabeçalho; separador<tab>datasetSplit.txt- arquivo texto com duas colunas, a primeira com o índice da sentença (do arquivo anterior) e a segunda com o índice indicando se a sentença deve ser usada para treino (1), teste (2) ou validação (3); com cabeçalho; separador ‘,‘dictionary.txt- arquivo texto com duas colunas, a primeira com o texto de uma sentença (ou subparte) e a segunda com o índice desse particionamento do texto; sem cabeçalho; separador ‘|‘sentiment_labels.txt- arquivo texto com duas colunas, a primeira com o índice da partição (do arquivo anterior) e a segunda com um número decimal entre 0 e 1 com o valor do sentimento; com cabeçalho; separador ‘|‘
Os índices usado em datasetSentences.txt e datasetSplit.txt são os mesmos. Os índices usados em dictionary.txt e sentiment_labels.txt também correspondem. Contudo, esses índices são diferentes entre si.
Toda sentença em datasetSentences.txt está presente em dictionary.txt, a menos da diferença de alguns caracteres com erro de codificação ou representação diferente. Exemplo: enquanto no primeiro arquivo aparece ‘é’, no segundo aparece o correto ‘é’; no primeiro arquivo é usado ‘-LRB-’ e no segundo ‘(’. Essas diferenças foram identificadas manualmente e são usadas para corrigir o texto das sentenças.
Como resultado, é possível estabelecer a relação entre o primeiro conjunto de índices com o segundo conjunto de índices para aplicar a separação do dataset (treino, teste e validação) aos valores de sentimento que são usados no modelo de classificação de sentimento. Nesse trabalho, diferente do que é feito no paper, essa separação não é usada com os modelos do Paragraph2vec (simplificação do treinamento).
Modelagem:
phrases: Dict[str, str]- dicionário que mapeia o texto de cada documento (sentença e subpartes) no identificador usado no dataset (phrase id), é usado para o treino do Paragraph2vectrain_sentiment: List[Tuple[str, float]]- lista da associação do identificador do documento com o valor do sentimento, é usada para treino do classificador de sentimentovalid_sentiment: List[Tuple[str, float]]- lista da associação do identificador do documento com o valor do sentimento, é usada para avaliação do classificador de sentimentotest_sentiment: List[Tuple[str, float]]- lista da associação do identificador do documento com o valor do sentimento, é usada para avaliação do classificador de sentimento
O mesmo identificador de documento é usado nessas variáveis (valor do item no dicionário e primeira posição da tupla nas listas).
Código do Download:
r = requests.get(
'http://nlp.stanford.edu/~socherr/stanfordSentimentTreebank.zip',
stream=True)
with open('stanfordSentimentTreebank.zip', 'wb') as f:
for chunk in r.iter_content(chunk_size=32768):
if chunk:
f.write(chunk)
with zipfile.ZipFile('stanfordSentimentTreebank.zip') as f:
files = [
'datasetSentences.txt',
'datasetSplit.txt',
'dictionary.txt',
'sentiment_labels.txt'
]
for filename in files:
with open(filename, 'wb') as fout:
fin = f.open('stanfordSentimentTreebank/' + filename)
shutil.copyfileobj(fin, fout)
Código da combinação dos arquivos:
phrases = dict()
with open('dictionary.txt') as f:
for line in f:
phrase_text, phrase_id = line.rstrip().split('|')
phrases[phrase_text] = phrase_id
sentiments = dict()
with open('sentiment_labels.txt') as f:
next(f) # skip header
for line in f:
phrase_id, sentiment_score = line.rstrip().split('|')
sentiments[phrase_id] = float(sentiment_score)
sentence_replace = {
'-LRB-': '(', '-RRB-': ')', 'á': 'á', 'à ': 'à', 'â': 'â', 'ã': 'ã',
'é': 'é', 'è': 'è', 'Ã': 'í', 'ï': 'ï', 'ó': 'ó', 'ô': 'ô', 'ö': 'ö',
'û': 'û', 'ü': 'ü', 'æ': 'æ', 'ç': 'ç', 'ñ': 'ñ', '2Â': '2', '8Â': '8'}
def text_fix(txt):
for k, v in sentence_replace.items():
if k in txt:
txt = txt.replace(k, v)
return txt
sentences = dict()
with open('datasetSentences.txt') as f:
next(f) # skip header
for line in f:
sentence_id, sentence_text = line.rstrip().split('\t')
sentences[sentence_id] = text_fix(sentence_text)
sentence_to_phrase = dict(
(sentence_id, phrases[sentence_text])
for sentence_id, sentence_text in sentences.items())
train_sentiment = list()
valid_sentiment = list()
test_sentiment = list()
splits = {'1': train_sentiment, '2': test_sentiment, '3': valid_sentiment}
with open('datasetSplit.txt') as f:
next(f) # skip header
for line in f:
sentence_id, split = line.rstrip().split(',')
phrase_id = sentence_to_phrase[sentence_id]
sentiment_score = sentiments[phrase_id]
splits[split].append((phrase_id, sentiment_score))
As variáveis phrases, train_sentiment, valid_sentiment e test_sentiment ainda precisam ser codificadas para processamento no treinamento do Paragraph2vec e do classificador de sentimento.
Análise
Um vocabulário é criado para codificar as palavras em números que são usados como índices, tanto na matriz que contém os vetores que representam as palavras (DM) quanto na numeração das classes do Softmax (DM e DBOW). Os documentos também são numerados como índices para a matriz que contém os vetores que os representam.
Dessa forma, cada documento e texto correspondente é transformado em sequencia de números usando os dicionário do vocabulário de palavras e documentos. Essa é uma transformação necessária tanto para o aprendizado no treinamento quanto para a inferência.
Apenas palavras presentes nesse vocabulário são ‘conhecidas’ pelo modelo (vetores de palavras e classes do Softmax). É possível fazer o treinamento com novos documentos usando as palavras fixas do vocabulário e só treinando uma nova representação de documentos com a adição dos novos (assim é proposto no paper), contudo, esse processo não é feito nesse trabalho.
O dataset é formado por sentenças completas (correspondem ao comentários propriamente) e essas sentenças são particionadas em sequencias menores que foram anotadas manualmente com o valor do sentimento. Seguindo o protocolo do paper, cada partição é considerada como um documento único e somente as sentenças completas são usadas na análise de sentimento.
Dessa forma, são 239.232 documentos para o treinamento do Paragraph2vec, dos quais 11.855 desses documentos (juntamente com o valor do sentimento) são usados para o classificador de sentimento.
Exemplos de sentenças completas:
The film provides some great insight into the neurotic mindset of all comics – even those who have reached the absolute top of the game .
Offers that rare combination of entertainment and education .
Perhaps no picture ever made has more literally showed that the road to hell is paved with good intentions .
Steers turns in a snappy screenplay that curls at the edges ; it ’s so clever you want to hate it .
Os documentos têm entre 1 e 56 tokens, com a média de 7,8 e desvio padrão de 7,1. Para o treinamento, quando a janela é maior que o número de tokens do documento, o texto do documento é prefixado com um token NULL (zero) para completar o tamanho mínimo.
Tamanhos mais comuns:
- 37.489 documentos com 2 tokens
- 30.949 documentos com 3 tokens
- 22.346 documentos com 1 token
- 21.403 documentos com 4 tokens
- 16.711 documentos com 5 tokens
Portanto, os documentos desse dataset são curtos e capturar o sinal de sentimento desse texto é bastante difícil (Paragraph2vec obteve o estado-da-arte na época do paper).
Do total de documentos, são 1.855.983 tokens no total (palavras e símbolos de pontuação), com 19.795 tokens únicos. Considerando apenas tokens com pelo menos 5 ocorrências, são 19.212 (apenas 583 tokens muito pouco frequentes, uma vez que as partições repetem o conteúdo das sentenças completas - esses tokens são mapeados como ‘unknown’).
Os tokens mais frequentes são:
the(83.351),(70.577)a(58.742)and(51.804)of(51.771).(38.004)to(36.937)'s(28.200)is(23.073)in(22.602)
Amostra de tokens com menos de 5 ocorrência (mapeados como ‘unknown’):
ryosuke, schnieder, sensitively, snoots, spectators, spiderman, symbolically, theirs, topkapi, touché, two-bit, ub, unflinchingly, unintelligible, unspools, unsurprisingly, vereté, ou, overburdened
Construção do vocabulário:
token_to_id: Dict[str, int]- dicionário que mapeia a palavra no identificador (índice)token_from_id: Dict[int, str]- dicionário reverso que mapeia o identificador (índice) na palavradocument_to_id: Dict[str, int]- dicionário que mapeia a referência do documento no identificador (índice)document_from_id: Dict[int, str]- dicionário reverso que mapeia o identificador (índice) na referência do documento
No dataset, a referência do documento é o phrase id; o propósito de se criar um índice próprio é para generalizar o processo quando se trata de documentos que não estejam previamente indexados.
min_freq = 5
text_raw = list((phrase_ref, phrase_text)
for phrase_text, phrase_ref in phrases.items())
text_tokens = list((ref, text.lower().split()) for ref, text in text_raw)
tokens_flat = list(token for _, tokens in text_tokens for token in tokens)
tokens_freq = collections.Counter(tokens_flat).most_common()
tokens_vocab = list(token for token, freq in tokens_freq if freq >= min_freq)
vocabulary_size = len(tokens_vocab) + 2
NULL_ID = 0
UNK_ID = 1
token_to_id = dict(
(token, token_id) for token_id, token in enumerate(tokens_vocab, 2))
token_to_id['NULL'] = NULL_ID
token_to_id['UNK'] = UNK_ID
token_from_id = dict(
(token_id, token) for token, token_id in token_to_id.items())
collection_size = len(text_raw)
document_to_id = dict(
(doc_ref, doc_id) for doc_id, (doc_ref, _) in enumerate(text_raw))
document_from_id = dict(
(doc_id, doc_ref) for doc_ref, doc_id in document_to_id.items())
Transformação do Texto
Para esse trabalho, a transformação escolhida foi criar uma lista que contem todos os tokens do conjunto de textos e vincular o documento desse token formando o par (índice do documento, índice do token) - o motivo para esse formato é manter a similaridade com o formato usado no treinamento do Word2vec; Contudo, para o treinamento do Paragraph2vec, cada documento é tratado individualmente e não é necessário ter um stream único de tokens.
Transformação:
data: List[Tuple[int, int]]- lista dos pares de índices correspondentes aos documentos e tokens dos respectivos textos
data = list((document_to_id[doc_ref], token_to_id.get(token, UNK_ID))
for doc_ref, tokens in text_tokens
for token in tokens)
Trecho inicial com os pares:
[(0, 255), (1, 255), (1, 44), (2, 255), (2, 27), (3, 255), (3, 2796), (4, 255), (4, 653), (5, 255)]
Tokens desse trecho inicial (nesse caso, o número do documento é o phrase id):
[(‘0’, ‘!’), (‘22935’, ‘!’), (‘22935’, “‘”), (‘18235’, ‘!’), (‘18235’, “”“), (‘179257’, ‘!’), (‘179257’, ‘alas’), (‘22936’, ‘!’), (‘22936’, ‘brilliant’), (‘40532’, ‘!’)]
Transformação do Sentimento
A escala definida para o dataset (ver paper do dataset) estipula que os valores entre 0,0 e 0,5 representam sentimento negativo (níveis) e os valores entre 0,5 e 1,0 representam sentimento positivo (níveis); o valor 0,5 propriamente é neutro.
Nesse trabalho, a análise de sentimento é feita por um classificador binário, portanto, essa escala de valores é transformada em duas classes: 0 para negativo (valores menores ou igual a 0,5) e 1 para positivo (valores maiores que 0,5).
Transformação:
train_data, valid_data, test_data: List[Tuple[int, int]]- lista dos índices dos documentos associados com a classe de sentimento correspondente
threshold = 0.5
train_data = list((document_to_id[doc_ref], int(score > threshold))
for doc_ref, score in train_sentiment)
valid_data = list((document_to_id[doc_ref], int(score > threshold))
for doc_ref, score in train_sentiment)
test_data = list((document_to_id[doc_ref], int(score > threshold))
for doc_ref, score in test_sentiment)
Com essa transformação:
Treino
8.544 documentos com 4.300 positivos e 4.244 negativos
Validação
1.101 documentos com 543 positivos e 558 negativos
Teste
2.210 documentos com 1.067 positivos e 1.143 negativos
(os documentos são sentenças completas)
…
Ao final do procedimento descrito nesse tópico, 8 resultados são produzidos:
token_to_id: Dict[str, int]- dicionário que mapeia o token no identificador (índice)token_from_id: Dict[int, str]- dicionário reverso que mapeia o identificador (índice) no tokendocument_to_id: Dict[str, int]- dicionário que mapeia a referência do documento (phrase id) no identificador (índice)document_from_id: Dict[int, str]- dicionário reverso que mapeia o identificador (índice) na referência do documento (phrase id)data: List[Tuple[int, int]]- lista dos pares de índices correspondentes aos documentos e tokens dos respectivos textostrain_data, valid_data, test_data: List[Tuple[int, int]]- lista dos índices dos documentos associados com a classe de sentimento correspondente (1 positivo, 0 negativo)
Na sequencia, o código necessário para aprender a representação vetorial é desenvolvido para os dois modelos.
Distributed Memory (DM)
O DM é o modelo do Paragraph2vec que maximiza a probabilidade de predizer a última palavra a partir da observação do vetor do documento combinado com as palavras anteriores em uma janela de palavras que desliza sobre o texto. Para calcular essa probabilidade, é usada uma camada única que tem como entrada a concatenação dos vetores do documento com os das palavras (ou a média) e a probabilidade de cada palavras possíveis como saída. O erro é calculado pela diferença entre a distribuição de probabilidade da saída e a última palavra da janela. Os pesos da camada de predição, os vetores de palavras e os vetores de documentos são corrigidos pelo gradiente.
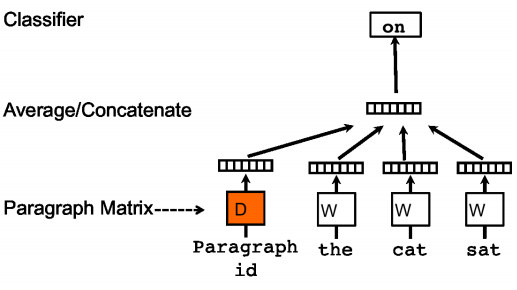
(imagem do paper Distributed Representations of Sentences and Documents)
O processo consiste em:
- Função de Entrada: função que percorre os dados criando lotes (batches) de entrada e saída para treinar o modelo usando gradiente
- Grafo do Modelo: descrição das operações que definem o fluxo e transformações dos dados para cálculo do erro (esse grafo permite que o TensorFlow calcule o gradiente e atualize as variáveis)
…
Entrada
Para o treinamento do DM, o texto do documento é amostrado em janelas de tamanho fixo que se deslocam palavra a palavra. Cada janela produz um exemplo, consistindo de três componentes: o índice do documento, o conjunto de índice das palavras iniciais e o índice da última palavra. Documentos com menos palavras do que o tamanho da janela são prefixados com o token NULL (zero). Com isso, todo documento produz pelo menos um exemplo.
A listagem de código corresponde a essa descrição e é formado por 4 funções. A função count_windows conta o número de exemplos (documentos menores que a janela produzem 1 exemplo, os demais tem 1 exemplo com o tamanho da janela mais o número de tokens restantes para novas janelas, cada uma produzindo um exemplo). A função slice_document reconstrói os tokens dos documentos (assumindo ordem) e preenche a primeira janela. A função examples_generator_dm faz o deslizamento da janela emitindo os exemplos. A função input_dm embaralha os exemplos e quebra em lotes de processamento (o último lote pode ter menos exemplos do que os demais).
Código:
def count_windows(data, window_size):
doc_length = collections.Counter(doc_id for doc_id, _ in data).values()
windows_per_doc = (1 + max(0, length - window_size)
for length in doc_length)
return sum(windows_per_doc)
def slice_document(data, window_size, pad_value=NULL_ID):
doc_id, token_id = data.popleft()
window = collections.deque(maxlen=window_size)
window.append(token_id)
tail = collections.deque()
while data and data[0][0] == doc_id:
_, token_id = data.popleft()
if len(window) < window_size:
window.append(token_id)
else:
tail.append(token_id)
pad_size = window_size - len(window)
if pad_size > 0:
window.extendleft([pad_value] * pad_size)
return doc_id, window, tail
def examples_generator_dm(data, window_size):
num_examples = count_windows(data, window_size)
data_tail = collections.deque(data)
doc_id, window, tail = None, None, None
for _ in range(num_examples):
if not tail:
doc_id, window, tail = slice_document(data_tail, window_size)
else:
window.append(tail.popleft())
_window = list(window)
yield doc_id, _window[:-1], _window[-1]
def input_dm(data, batch_size, window_size, shuffle=True):
examples = list(examples_generator_dm(data, window_size))
if shuffle:
random.shuffle(examples)
num_examples = len(examples)
while num_examples > 0:
batch_size_i = min(batch_size, num_examples)
doc_batch = np.ndarray(shape=(batch_size_i, 1), dtype=np.int32)
words_batch = \
np.ndarray(shape=(batch_size_i, window_size-1), dtype=np.int32)
target_batch = np.ndarray(shape=(batch_size_i, 1), dtype=np.int32)
for i in range(batch_size_i):
doc_id, words, target = examples.pop()
doc_batch[i, 0] = doc_id
words_batch[i, :] = words
target_batch[i, 0] = target
num_examples -= batch_size_i
yield doc_batch, words_batch, target_batch
Exemplo:
batch_size = 4
window_size = 3
num_iters = 2
data_iter = input_dm(data, batch_size, window_size)
for k in range(1, num_iters+1):
print('Batch {}\n'.format(k))
doc_batch, words_batch, target_batch = next(data_iter)
for i in range(batch_size):
doc_ref = document_from_id[doc_batch[i, 0]]
words = ' '.join(token_from_id[token_id]
for token_id in words_batch[i])
target = token_from_id[target_batch[i, 0]]
print('{}: {} -> {}'.format(doc_ref, words, target))
print()
del data_iter
Batch 1
147311: makes for -> a
144793: to pose -> as
189782: , empathy -> and
189401: will need -> all
Batch 2
225875: were made -> for
189904: at war -> ,
150170: saw : -> evil
68902: tired as -> its
…
Modelo
Para o treinamento do DM, o erro é calculado para a predição da última palavra da janela usando Softmax sobre todas as palavras possíveis, a partir do vetor do documento combinado com os das palavras iniciais. O grafo consiste em receber o índice do documento, os índices das palavras iniciais, transformar esses índices nos vetores correspondentes, combinar esses vetores (concatenação ou média), fazer a projeção linear da dimensão combinada para o número de palavras possíveis, calcular a distribuição de probabilidade e calcular a diferença com o índice da última palavra da janela. Esse processamento é feito em lote. O TensorFlow faz o cálculo do gradiente e propaga as correções para as variáveis do modelo (vetores de documentos, vetores de palavras e projeção).
O número de palavas possíveis (classes do Softmax) é considerável e torna o cálculo exato do erro computacionalmente caro. Uma forma de tornar esse problema tratável é usando amostra de algumas classes e fazer o cálculo do erro aproximado.
O TensorFlow já tem a implementação desse cálculo na função tf.nn.sampled_softmax_loss.
Grafo do Modelo:
Os tensores de entrada X_doc, X_words e y correspondem ao lotes gerados pela Função de Entrada com o tamanho do lote substituído por None, indicando uma dimensão variável (definida na execução do grafo). O vetor NULL é uma constante que representa o token NULL e não é um parâmetro a ser aprendido.
A contrução do modelo linha a linha é feita no Notebook.
def model_dm(collection_size, vocabulary_size, embedding_size, window_size,
num_sampled, linear_input='concatenate'):
X_doc = tf.placeholder_with_default([[0]],
shape=(None, 1),
name='X_doc')
X_words = tf.placeholder_with_default([[0]*(window_size-1)],
shape=(None, window_size-1),
name='X_words')
y = tf.placeholder_with_default([[0]],
shape=(None, 1),
name='y')
doc_embeddings = tf.Variable(
tf.random_uniform(shape=(collection_size, embedding_size),
minval=-1.0, maxval=1.0),
name='doc_embeddings')
NULL = tf.zeros(shape=(1, embedding_size))
word_embeddings_ = tf.Variable(
tf.random_uniform(shape=(vocabulary_size - 1, embedding_size),
minval=-1.0, maxval=1.0))
word_embeddings = tf.concat([NULL, word_embeddings_], axis=0,
name='word_embeddings')
D_embed = tf.nn.embedding_lookup(doc_embeddings, X_doc)
W_embed = tf.nn.embedding_lookup(word_embeddings, X_words)
X_embed = tf.concat([D_embed, W_embed], axis=1)
if linear_input == 'concatenate':
linear_input_size = window_size * embedding_size
X_linear = tf.reshape(X_embed, [-1, linear_input_size])
elif linear_input == 'average':
linear_input_size = embedding_size
X_linear = tf.reduce_mean(X_embed, axis=1)
W_linear = tf.Variable(
tf.truncated_normal(shape=(vocabulary_size, linear_input_size),
stddev=1.0 / np.sqrt(linear_input_size)),
name='W')
b_linear = tf.Variable(
tf.zeros(shape=(vocabulary_size,)),
name='b')
with tf.name_scope('loss'):
sampled_loss = tf.nn.sampled_softmax_loss(weights=W_linear,
biases=b_linear,
inputs=X_linear,
labels=y,
num_sampled=num_sampled,
num_classes=vocabulary_size)
loss = tf.reduce_mean(sampled_loss, name='mean')
inputs = [X_doc, X_words, y]
embeddings = [doc_embeddings, word_embeddings]
return inputs, embeddings, loss
Exemplo:
batch_size = 4
window_size = 3
vocabulary_size = 20
collection_size = 5
embedding_size = 3
num_sampled = 2
X_doc_batch = np.random.randint(low=0,
high=collection_size,
size=(batch_size, 1),
dtype=np.int32)
X_words_batch = np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size, window_size-1),
dtype=np.int32)
y_batch = np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size, 1),
dtype=np.int32)
data_batch = (X_doc_batch, X_words_batch, y_batch)
with tf.Graph().as_default() as graph, \
tf.Session(graph=graph) as session:
inputs, embeddings, loss_op = \
model_dm(collection_size,
vocabulary_size,
embedding_size,
window_size,
num_sampled)
tf.global_variables_initializer().run()
data_feed = dict(zip(inputs, data_batch))
loss, doc_embeddings, word_embeddings = \
session.run([loss_op, *embeddings], data_feed)
print('Average loss:\n\n{:,.3f}\n'.format(loss))
print('Document embeddings:\n\n{}\n'.format(doc_embeddings))
print('Word embeddings:\n\n{}\n'.format(word_embeddings))
Average loss:
0.834
Document embeddings:
[[-0.20155668 0.89437795 0.86981654]
[ 0.27514839 0.03905988 -0.16025376]
[ 0.50432229 -0.61670518 -0.35366344]
[ 0.42855215 0.33345056 -0.82449532]
[-0.72761488 0.90715146 -0.54655051]]
Word embeddings:
[[ 0. 0. 0. ]
[ 0.81689048 0.05420208 0.39406753]
[ 0.10489869 0.45829964 0.05955195]
[-0.07528186 -0.21810842 -0.93897033]
[ 0.19691038 -0.35718656 0.99723196]
[ 0.1321466 0.43886185 0.96905661]
[-0.91746879 -0.4718976 0.80058098]
[-0.20765495 -0.42693996 0.58628917]
[ 0.51723647 -0.18970108 0.35841203]
[-0.47584915 0.60480165 0.26137257]
[-0.94035411 0.36131597 -0.22726011]
[ 0.53713584 0.10812354 0.83878994]
[ 0.18764162 -0.1827848 0.68616128]
[ 0.54342461 0.68947959 0.67821264]
[-0.47808957 0.98007965 0.17656755]
[ 0.11975074 -0.99398828 -0.22357965]
[-0.48503876 -0.7004745 -0.40049338]
[-0.21140122 0.93470955 -0.18008828]
[-0.64276743 -0.36833382 0.66008258]
[ 0.23376918 0.37836504 -0.76408005]]
…
Ao final do procedimento descrito nesse tópico, 2 resultados são produzidos:
input_dm(data: List[Tuple[int, int]], batch_size: int, window_size: int, shuffle:bool) -> Iterable[Tuple[np.ndarray, np.ndarray, np.ndarray]]- função que percorre os dados criando lotes (batches) de entrada e saída esperada (essa função é um generator)def model_dm(collection_size: int, vocabulary_size: int, embedding_size: int, window_size: int, num_sampled: int, linear_input: str) -> Tuple[List[tf.Tensor], List[tf.Tensor], tf.Tensor]- função que define o fluxo de transformações dos dados para cálculo do erro de predição usada no aprendizado da representação vetorial com TensorFlow
Na sequencia, o mesmo procedimento é feito para o segundo modelo do Paragraph2vec, DBOW.
Distributed Bag-of-Words (DBOW)
O DBOW é o modelo do Paragraph2vec que maximiza a probabilidade de predizer uma amostra de palavras a partir da observação do vetor do documento em uma janela de palavras que desliza sobre o texto. Para calcular essa probabilidade, é usada uma camada única que tem como entrada o vetor do documento e a probabilidade de cada palavras possíveis como saída. O erro é calculado pela diferença entre a distribuição de probabilidade da saída e as palavras da janela. Os pesos da camada de predição e os vetores de documentos são corrigidos pelo gradiente.
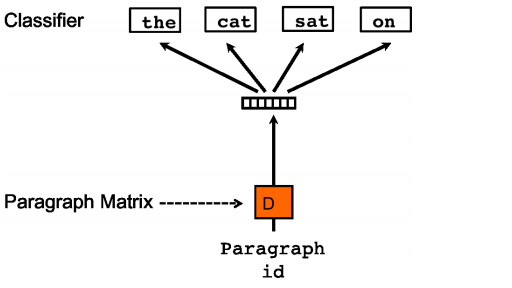
(imagem do paper Distributed Representations of Sentences and Documents)
O processo consiste em:
- Função de Entrada: função que percorre os dados criando lotes (batches) de entrada e saída para treinar o modelo usando gradiente
- Grafo do Modelo: descrição das operações que definem o fluxo e transformações dos dados para cálculo do erro (esse grafo permite que o TensorFlow calcule o gradiente e atualize as variáveis)
…
Entrada
Para o treinamento do DBOW, o texto do documento é amostrado em janelas de tamanho fixo que se deslocam palavra a palavra. Cada janela produz um exemplo, consistindo de dois componentes: o índice do documento e o conjunto de índice das palavras. Documentos com menos palavras do que o tamanho da janela são prefixados com o token NULL (zero). Com isso, todo documento produz pelo menos um exemplo.
A listagem de código corresponde a essa descrição e é formado por 4 funções. A função count_windows conta o número de exemplos (documentos menores que a janela produzem 1 exemplo, os demais tem 1 exemplo com o tamanho da janela mais o número de tokens restantes para novas janelas, cada uma produzindo um exemplo). A função slice_document reconstrói os tokens dos documentos (assumindo ordem) e preenche a primeira janela. A função examples_generator_dbow faz o deslizamento da janela emitindo os exemplos. A função input_dbow embaralha os exemplos e quebra em lotes de processamento (o último lote pode ter menos exemplos do que os demais).
Código:
def count_windows(data, window_size):
doc_length = collections.Counter(doc_id for doc_id, _ in data).values()
windows_per_doc = (1 + max(0, length - window_size)
for length in doc_length)
return sum(windows_per_doc)
def slice_document(data, window_size, pad_value=NULL_ID):
doc_id, token_id = data.popleft()
window = collections.deque(maxlen=window_size)
window.append(token_id)
tail = collections.deque()
while data and data[0][0] == doc_id:
_, token_id = data.popleft()
if len(window) < window_size:
window.append(token_id)
else:
tail.append(token_id)
pad_size = window_size - len(window)
if pad_size > 0:
window.extendleft([pad_value] * pad_size)
return doc_id, window, tail
def examples_generator_dbow(data, window_size):
num_examples = count_windows(data, window_size)
data_tail = collections.deque(data)
doc_id, window, tail = None, None, None
for _ in range(num_examples):
if not tail:
doc_id, window, tail = slice_document(data_tail, window_size)
else:
window.append(tail.popleft())
yield doc_id, list(window)
def input_dbow(data, batch_size, window_size, shuffle=True):
examples = list(examples_generator_dbow(data, window_size))
if shuffle:
random.shuffle(examples)
num_examples = len(examples)
while num_examples > 0:
batch_size_i = min(batch_size, num_examples)
doc_batch = np.ndarray(shape=(batch_size_i, 1), dtype=np.int32)
target_batch = \
np.ndarray(shape=(batch_size_i, window_size), dtype=np.int32)
for i in range(batch_size_i):
doc_id, words = examples.pop()
doc_batch[i, 0] = doc_id
target_batch[i, :] = words
num_examples -= batch_size_i
yield doc_batch, target_batch
Exemplo:
batch_size = 4
window_size = 3
num_iters = 2
data_iter = input_dbow(data, batch_size, window_size)
for k in range(1, num_iters+1):
print('Batch {}\n'.format(k))
doc_batch, target_batch = next(data_iter)
for i in range(batch_size):
doc_ref = document_from_id[doc_batch[i, 0]]
target = ' '.join(token_from_id[token_id]
for token_id in target_batch[i])
print('{} -> {}'.format(doc_ref, target))
print()
del data_iter
Batch 1
143054 -> standard , stiff
27216 -> or at your
44818 -> UNK one .
148672 -> to an idea
Batch 2
188754 -> is that it
66367 -> UNK the UNK
71173 -> analyze that ,
64057 -> a state of
…
Modelo
Para o treinamento do DBOW, o erro é calculado para a predição do conjunto de palavras da janela usando Softmax sobre todas as palavras possíveis, a partir do vetor do documento. O grafo consiste em receber o índice do documento, transformar esse índice no vetor correspondente, fazer a projeção linear da dimensão do vetor para o número de palavras possíveis, calcular a distribuição de probabilidade e calcular a diferença com o índice das palavras da janela. Esse processamento é feito em lote. O TensorFlow faz o cálculo do gradiente e propaga as correções para as variáveis do modelo (vetores de documentos e projeção).
O número de palavas possíveis (classes do Softmax) é considerável e torna o cálculo exato do erro computacionalmente caro. Uma forma de tornar esse problema tratável é usando amostra de algumas classes e fazer o cálculo do erro aproximado.
O TensorFlow já tem a implementação desse cálculo na função tf.nn.sampled_softmax_loss.
Grafo do Modelo:
Os tensores de entrada X e y correspondem ao lotes gerados pela Função de Entrada com o tamanho do lote substituído por None, indicando uma dimensão variável (definida na execução do grafo).
A construção do modelo linha a linha é feita no Notebook.
def model_dbow(collection_size, vocabulary_size, embedding_size, window_size,
num_sampled):
X = tf.placeholder_with_default([[0]],
shape=(None, 1),
name='X')
y = tf.placeholder_with_default([[0]*window_size],
shape=(None, window_size),
name='y')
doc_embeddings = tf.Variable(
tf.random_uniform(shape=(collection_size, embedding_size),
minval=-1.0, maxval=1.0),
name='doc_embeddings')
D_embed = tf.nn.embedding_lookup(doc_embeddings, X)
X_linear = tf.squeeze(D_embed, axis=1)
W_linear = tf.Variable(
tf.truncated_normal(shape=(vocabulary_size, embedding_size),
stddev=1.0 / np.sqrt(embedding_size)),
name='W')
b_linear = tf.Variable(
tf.zeros(shape=(vocabulary_size,)),
name='b')
with tf.name_scope('loss'):
sampled_loss = tf.nn.sampled_softmax_loss(weights=W_linear,
biases=b_linear,
inputs=X_linear,
labels=y,
num_sampled=num_sampled,
num_classes=vocabulary_size,
num_true=window_size)
loss = tf.reduce_mean(sampled_loss, name='mean')
inputs = [X, y]
return inputs, doc_embeddings, loss
Exemplo:
batch_size = 4
window_size = 3
vocabulary_size = 20
collection_size = 5
embedding_size = 3
num_sampled = 2
X_batch = np.random.randint(low=0,
high=collection_size,
size=(batch_size, 1),
dtype=np.int32)
y_batch = np.random.randint(low=0,
high=vocabulary_size,
size=(batch_size, window_size),
dtype=np.int32)
data_batch = (X_batch, y_batch)
with tf.Graph().as_default() as graph, \
tf.Session(graph=graph) as session:
inputs, embeddings, loss_op = \
model_dbow(collection_size,
vocabulary_size,
embedding_size,
window_size,
num_sampled)
tf.global_variables_initializer().run()
data_feed = dict(zip(inputs, data_batch))
loss, doc_embeddings = \
session.run([loss_op, embeddings], data_feed)
print('Average loss:\n\n{:,.3f}\n'.format(loss))
print('Document embeddings:\n\n{}\n'.format(doc_embeddings))
Average loss:
1.727
Document embeddings:
[[ 0.50691843 0.7200942 -0.51887631]
[-0.94016647 0.9350605 -0.42361689]
[-0.56953073 0.53575516 -0.64528918]
[-0.6075573 -0.09110403 0.89297009]
[ 0.75959897 0.24239826 0.66488004]]
…
Ao final do procedimento descrito nesse tópico, 2 resultados são produzidos:
input_dbow(data: List[Tuple[int, int]], batch_size: int, window_size: int, shuffle: bool) -> Iterable[Tuple[np.ndarray, np.ndarray]]- função que percorre os dados criando lotes (batches) de entrada e saída esperada (essa função é um generator)model_dbow(collection_size: int, vocabulary_size: int, embedding_size: int, window_size: int, num_sampled: int) -> Tuple[List[tf.Tensor], tf.Tensor, tf.Tensor]- função que define o fluxo de transformações dos dados para cálculo do erro de predição usada no aprendizado da representação vetorial com TensorFlow
Na sequencia, o código necessário para análise de sentimento usando as representações vetoriais é desenvolvido.
Sentiment Analysis
A representação vetorial aprendida com Paragraph2vec possui características da linguagem usada no texto. O princípio é que documentos que manifestam um mesmo sentimento teriam alguma evidência dessa relação no valor dos vetores. Para verificar essa propriedade, a proposta nesse trabalho é aprender um classificador linear diretamente sobre o vetor do documento para predizer o sentimento na forma de uma variável binária, indicando sentimento positivo ou negativo.
O modelo usado é Logistic Regression construído para ter como entrada o índice do documento e produzir na saída a probabilidade e a classe do sentimento.
…
Entrada
Para o treinamento do classificador de sentimento, um exemplo consiste de dois componentes: o índice do documento e a classe do sentimento (0 negativo, 1 positivo). Esses valores são a entrada e a saída esperada do modelo.
A função input_sentiment embaralha os exemplos e quebra em lotes de processamento (o último lote pode ter menos exemplos do que os demais).
def input_sentiment(data, batch_size, shuffle=True):
num_examples = len(data)
data_tail = collections.deque(data)
if shuffle:
random.shuffle(data_tail)
while num_examples > 0:
batch_size_i = min(batch_size, num_examples)
doc_batch = np.ndarray(shape=(batch_size_i, 1), dtype=np.int32)
target_batch = np.ndarray(shape=(batch_size_i, 1), dtype=np.int32)
for i in range(batch_size_i):
doc_id, sentiment = data_tail.popleft()
doc_batch[i, 0] = doc_id
target_batch[i, 0] = sentiment
num_examples -= batch_size_i
yield doc_batch, target_batch
Exemplo:
batch_size = 4
num_iters = 2
data_iter = input_sentiment(train_data, batch_size)
for k in range(1, num_iters + 1):
print('Batch {}\n'.format(k))
doc_batch, target_batch = next(data_iter)
for i in range(batch_size):
doc_ref = document_from_id[doc_batch[i, 0]]
sentiment_class = target_batch[i, 0]
print('{} -> {}'.format(doc_ref, sentiment_class))
print()
del data_iter
Batch 1
103759 -> 1
185148 -> 0
63222 -> 1
106733 -> 0
Batch 2
146719 -> 0
65261 -> 1
68385 -> 1
70026 -> 1
Modelo
Para o treinamento do classificador de sentimento, o erro é calculado para a predição da variável binária usando Cross Entropy, a partir dos pesos do vetor do documento. O grafo consiste em receber o índice do documento, transformar esse índice nos vetores correspondentes (do DM e do DBOW), combinar os vetores do mesmo documento, fazer a projeção linear, calcular a probabilidade (sigmoide) e calcular a diferença para a classe esperada. Esse processamento é feito em lote. O TensorFlow faz o cálculo do gradiente e propaga as correções para as variáveis do modelo (pesos da projeção).
Os vetores de documentos não fazem parte dos parâmetros a serem aprendidos com o modelo.
O TensorFlow salva em arquivo o grafo serializado com os valores das variáveis, incluindo os vetores dos documentos. Quando o modelo é carregado do arquivo, as variáveis são inicializadas com os valores usados quando o grafo foi salvo (ignorando o objeto de inicialização da variável). O aprendizado dos vetores de documentos é feito com outro grafo / sessão e precisam ser redefinidos para utilização desse modelo (substituindo os valores salvos). Essa operação está encapsulada no objeto
embeddings_inite é dessa forma que o aprendizado do Paragraph2vec é usado nesse modelo (não há ‘comunicação direta’ entre os modelos).A construção do modelo linha a linha é feita no Notebook.
def model_sentiment(collection_size, embedding_size, threshold=0.5):
X = tf.placeholder_with_default([[0]], shape=(None, 1), name='X')
y = tf.placeholder_with_default([[0]], shape=(None, 1), name='y')
embeddings_dm = tf.Variable(
tf.zeros(shape=(collection_size, embedding_size)),
trainable=False,
name='embeddings_dm')
embeddings_dbow = tf.Variable(
tf.zeros(shape=(collection_size, embedding_size)),
trainable=False,
name='embeddings_dbow')
X_dm = tf.nn.embedding_lookup(embeddings_dm, X)
X_dbow = tf.nn.embedding_lookup(embeddings_dbow, X)
X_embed = tf.concat([X_dm, X_dbow], axis=2)
X_linear = tf.squeeze(X_embed, axis=1)
W = tf.Variable(
tf.truncated_normal(shape=(2 * embedding_size, 1)),
name='W')
b = tf.Variable(
tf.zeros(shape=(1,)),
name = 'b')
logits = tf.nn.xw_plus_b(X_linear, W, b)
y_prob = tf.sigmoid(logits)
y_hat = tf.cast(tf.greater_equal(y_prob, threshold), tf.int32)
loss = tf.losses.sigmoid_cross_entropy(y, logits)
embeddings_dm_input = tf.placeholder(
tf.float32,
shape=(collection_size, embedding_size),
name='embeddings_dm_input')
embeddings_dbow_input = tf.placeholder(
tf.float32,
shape=(collection_size, embedding_size),
name='embeddings_dbow_input')
embeddings_init_op = tf.group(
tf.assign(embeddings_dm, embeddings_dm_input),
tf.assign(embeddings_dbow, embeddings_dbow_input))
embeddings_inputs = [embeddings_dm_input, embeddings_dbow_input]
embeddings_init = (embeddings_inputs, embeddings_init_op)
inputs = [X, y]
predictions = [y_prob, y_hat]
return embeddings_init, inputs, predictions, loss
Exemplo:
batch_size = 4
collection_size = 5
embedding_size = 3
embeddings1 = np.random.randn(collection_size,
embedding_size)
embeddings2 = np.random.randn(collection_size,
embedding_size)
embeddings = [embeddings1.astype(np.float32),
embeddings2.astype(np.float32)]
X_batch = np.random.randint(low=0,
high=collection_size,
size=(batch_size, 1),
dtype=np.int32)
y_batch = np.random.randint(low=0,
high=2,
size=(batch_size, 1),
dtype=np.int32)
data_batch = (X_batch, y_batch)
with tf.Graph().as_default() as graph, \
tf.Session(graph=graph) as session:
init, inputs, predictions, loss_op = \
model_sentiment(collection_size, embedding_size)
tf.global_variables_initializer().run()
init_feed = dict(zip(init[0], embeddings))
session.run(init[1], init_feed)
data_feed = dict(zip(inputs, data_batch))
loss, y_prob, y_hat = session.run([loss_op, *predictions],
data_feed)
print('Average loss: {:,.3f}\n'.format(loss))
for i in range(batch_size):
print('y={}, ŷ={} ({:.2f}%)'.format(y_batch[i, 0],
y_hat[i, 0],
100 * y_prob[i, 0]))
Average loss: 1.257
y=1, ŷ=1 (59.37%)
y=0, ŷ=1 (59.37%)
y=0, ŷ=1 (95.42%)
y=1, ŷ=1 (59.37%)
…
Ao final do procedimento descrito nesse tópico, 2 resultados são produzidos:
input_sentiment(data: List[Tuple[int, int]], batch_size: int, shuffle: bool) -> Iterable[Tuple[np.ndarray, np.ndarray]]- função que percorre os dados criando lotes (batches) de entrada e saída esperada (essa função é um generator)model_sentiment(collection_size: int, embedding_size: int, threshold: float) -> Tuple[Tuple[List[tf.Tensor], tf.Operation], List[tf.Tensor], List[tf.Tensor], tf.Tensor]- função que define o fluxo de transformações dos dados para cálculo do erro de predição usada na classificação de sentimento com TensorFlow.
Na sequencia, são mostrados os experimentos com ambos os modelos do Paragraph2vec e a aplicação de análise de sentimento.
Experimentos
O treinamento é dividido em duas etapas: primeiro, o aprendizado da representação vetorial dos dois modelos do Paragraph2vec, e; segundo, aprendizado do classificador de sentimento. O resultado da representação vetorial é usado no classificador de sentimento. Na análise, esse treinamento é feito de forma intercalada para avaliar que o aprendizado em um realmente tem efeito no outro.
Ambas as etapas consistem do mesmo processo: construir o grafo de operações que calcula a função objetivo a partir dos dados e aplicar um algoritmo de otimização que minimiza essa função objetivo (usando o gradiente). Durante o treinamento, é possível acompanhar no TensorBoard a evolução das métricas que são colocadas nos grafos.
Para usar o TensorBoard é necessário executar o servidor no console e acessar pelo navegador:
O TensorBoard é instalado pelo pacote do TensorFlow. O executável fica na pasta em que o Python define a instalação de binários.
$ tensorboard --logdir=<PASTA_DE_EXECUÇÃO>
Abrir o navegador no endereço:
Paragraph2vec
Código da função que adiciona o algoritmo de otimização:
O algoritmo de otimização usado é o Adagrad. Os resultados mostram que tem um bom desempenho nos modelos do NLP.
def opt_adagrad(loss, learning_rate=1.0):
return tf.contrib.layers.optimize_loss(
loss=loss,
optimizer='Adagrad',
learning_rate=learning_rate,
global_step=tf.train.get_global_step(),
summaries=['loss'])
Código da função que executa o treinamento:
A métrica do Erro Médio é adicionada ao grafo através da função
metrics_average_lossque usa a implementação oferecida na função tf.metrics.mean. O valor dessa métrica é vinculado a um sumário escalar para visualização do gráfico no TensorBoard.As variáveis dessa métrica são atualizadas por lote e o valor calculado no final da época quando todos os sumários são executados e salvos no log.
def metrics_average_loss(loss_op, summary_key):
value, update = tf.metrics.mean(loss_op, name='metrics/average_loss')
*_, total, count = tf.local_variables()
reset = tf.variables_initializer([total, count])
tf.summary.scalar('average_loss', value, [summary_key])
return value, update, reset
def train_embeddings(model_fn, input_fn, opt_fn, num_epochs=1, last_print=True,
model_dir='/tmp/embedding_model', remove_model=True):
if remove_model and os.path.isdir(model_dir):
shutil.rmtree(model_dir)
EPOCH_SUMMARIES = 'epoch_summaries'
with tf.Graph().as_default():
global_step = tf.train.create_global_step()
inputs, embeddings, loss_op = model_fn()
train_op = opt_fn(loss_op)
avg_tensor, avg_op, avg_reset = \
metrics_average_loss(loss_op, EPOCH_SUMMARIES)
epoch_summary_op = tf.summary.merge_all(EPOCH_SUMMARIES)
with tf.train.MonitoredTrainingSession(
checkpoint_dir=model_dir) as session:
for epoch in range(1, num_epochs+1):
#print('Epoch {}...'.format(epoch))
for data_batch in input_fn():
data_feed = dict(zip(inputs, data_batch))
session.run([train_op, avg_op], data_feed)
epoch_summary_proto, step_ = session.run([epoch_summary_op,
global_step])
summary_writer = tf.summary.FileWriterCache.get(model_dir)
summary_writer.add_summary(epoch_summary_proto, step_)
summary_writer.flush()
avg_loss = session.run(avg_tensor)
session.run(avg_reset)
embeddings_ = session.run(embeddings)
tf.summary.FileWriterCache.clear()
if last_print:
print('Last average loss: {:.4f}'.format(avg_loss))
return embeddings_
Na sequencia, essas funções são usadas no aprendizado da representação vetorial dos documentos com os dois modelos do Paragraph2vec.
Treinamento do DM:
%%timeé uma diretiva do Jupyter para medir o tempo de execução de uma célula - caso a execução desse código não seja no Jupyter, é necessário remover essa linha.
%%time
collection_size = len(document_to_id)
vocabulary_size = len(token_to_id)
embedding_size = 25
window_size = 4
num_sampled = 100
batch_size = 64
model_fn = lambda: model_dm(collection_size,
vocabulary_size,
embedding_size,
window_size,
num_sampled,
linear_input='average')
input_fn = lambda: input_dm(data,
batch_size,
window_size)
embeddings_dm, embeddings_dm_words = \
train_embeddings(model_fn,
input_fn,
opt_adagrad,
num_epochs=25,
model_dir='pv_dm')
Last average loss: 1.2406
CPU times: user 55min 53s, sys: 1min 52s, total: 57min 46s
Wall time: 36min 7s
Erro Médio por Época:
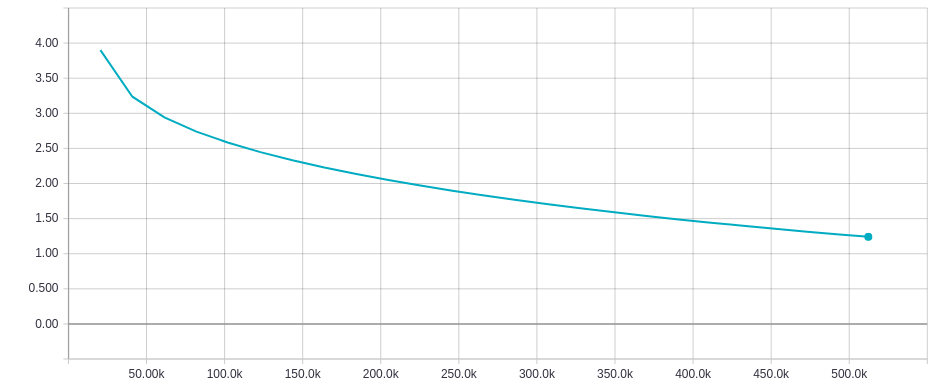
A métrica do Erro Médio tem o comportamento esperado: conforme o treinamento evolui, o erro por época diminui.
Treinamento do DBOW:
%%timeé uma diretiva do Jupyter para medir o tempo de execução de uma célula - caso a execução desse código não seja no Jupyter, é necessário remover essa linha.
%%time
collection_size = len(document_to_id)
vocabulary_size = len(token_to_id)
embedding_size = 25
window_size = 4
num_sampled = 100
batch_size = 64
model_fn = lambda: model_dbow(collection_size,
vocabulary_size,
embedding_size,
window_size,
num_sampled)
input_fn = lambda: input_dbow(data,
batch_size,
window_size)
embeddings_dbow = train_embeddings(model_fn,
input_fn,
opt_adagrad,
num_epochs=25,
model_dir='pv_dbow')
Last average loss: 2.9703
CPU times: user 48min 49s, sys: 1min 30s, total: 50min 20s
Wall time: 33min 54s
Erro Médio por Época:
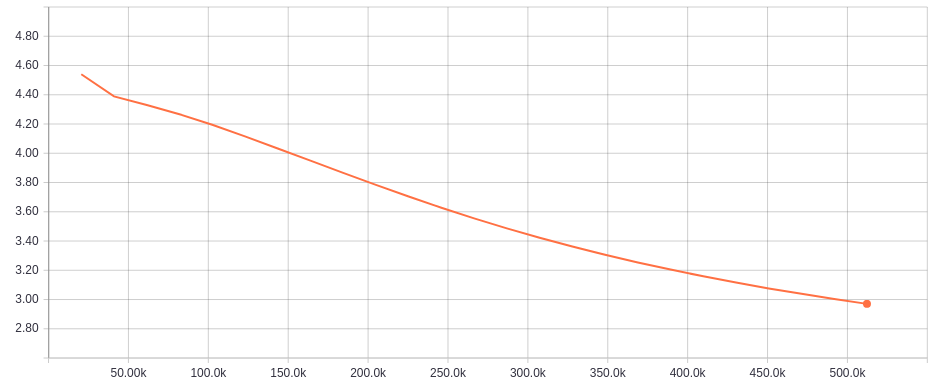
A métrica do Erro Médio tem o comportamento esperado: conforme o treinamento evolui, o erro por época diminui.
Análise de Sentimento
Código da função que adiciona o algoritmo de otimização:
O algoritmo de otimização usado é o FTRL. Esse é um algoritmo desenvolvido pelo Google tem um bom desempenho em modelos de regressão linear (ver publicação).
def opt_ftrl(loss, learning_rate=0.1):
return tf.contrib.layers.optimize_loss(
loss=loss,
optimizer='Ftrl',
learning_rate=learning_rate,
global_step=tf.train.get_global_step(),
summaries=['loss'])
Código da função que executa o treinamento:
Além da métrica do Erro Médio (função
metrics_average_lossanterior), é adicionada mais duas métricas relevantes para análise do modelo de classificação binária: a Acurácia e a AUC ROC.A métrica da Acurácia é adicionada ao grafo através da função
metrics_accuracyque usa a implementação oferecida na função tf.metrics.accuracy. O valor dessa métrica é vinculado a um sumário escalar para visualização do gráfico no TensorBoard.A métrica da AUC ROC é adicionada ao grafo através da função
metrics_aucque usa a implementação oferecida na função tf.metrics.auc. O valor dessa métrica é vinculado a um sumário escalar para visualização do gráfico no TensorBoard.No caso do dataset de treino, as variáveis dessas métricas são atualizadas por lote e os valores são calculados no final da época. No caso do dataset de validação, os valores das métricas são calculados em uma única execução no final da cada época.
No final da época, todos os sumários são executados e salvos no log.
def metrics_accuracy(mode, labels, predictions, summary_key):
value, update = tf.metrics.accuracy(labels=labels,
predictions=predictions,
name='metrics/accuracy/' + mode)
*_, total, count = tf.local_variables()
reset = tf.variables_initializer([total, count])
tf.summary.scalar('accuracy/' + mode, value, [summary_key])
return value, update, reset
def metrics_auc(mode, labels, predictions, summary_key):
value, update = tf.metrics.auc(labels=labels,
predictions=predictions,
name='metrics/auc/' + mode)
*_, tp, tn, fp, fn = tf.local_variables()
reset = tf.variables_initializer([tp, tn, fp, fn])
tf.summary.scalar('auc/' + mode, value, [summary_key])
return value, update, reset
def train_sentiment_pv(model_fn, input_fn, opt_fn, embeddings,
eval_data, num_epochs=1, last_print=True,
model_dir='/tmp/classifier_model', remove_model=True):
if remove_model and os.path.isdir(model_dir):
shutil.rmtree(model_dir)
EPOCH_SUMMARIES = 'epoch_summaries'
with tf.Graph().as_default():
global_step = tf.train.create_global_step()
init, inputs, predictions, loss_op = model_fn()
train_op = opt_fn(loss_op)
avg_tensor, avg_op, avg_reset = \
metrics_average_loss(loss_op, EPOCH_SUMMARIES)
_, y = inputs
y_prob, y_hat = predictions
auc_tensor, auc_op, auc_reset = \
metrics_auc('train', y, y_prob, EPOCH_SUMMARIES)
auc_eval_tensor, auc_eval_op, auc_eval_reset = \
metrics_auc('eval', y, y_prob, EPOCH_SUMMARIES)
acc_tensor, acc_op, acc_reset = \
metrics_accuracy('train', y, y_hat, EPOCH_SUMMARIES)
acc_eval_tensor, acc_eval_op, acc_eval_reset = \
metrics_accuracy('eval', y, y_hat, EPOCH_SUMMARIES)
eval_feed = dict(zip(inputs, eval_data))
epoch_summary_op = tf.summary.merge_all(EPOCH_SUMMARIES)
loop_ops = [train_op, avg_op, auc_op, acc_op]
eval_ops = [auc_eval_op, acc_eval_op]
reset_ops = [avg_reset, auc_reset, acc_reset,
auc_eval_reset, acc_eval_reset]
with tf.train.MonitoredTrainingSession(
checkpoint_dir=model_dir) as session:
init_feed = dict(zip(init[0], embeddings))
session.run(init[1], init_feed)
for epoch in range(1, num_epochs+1):
#print('Epoch {}...'.format(epoch))
for data_batch in input_fn():
data_feed = dict(zip(inputs, data_batch))
session.run(loop_ops, data_feed)
session.run(eval_ops, eval_feed)
epoch_summary_proto, step_ = session.run([epoch_summary_op,
global_step])
summary_writer = tf.summary.FileWriterCache.get(model_dir)
summary_writer.add_summary(epoch_summary_proto, step_)
summary_writer.flush()
avg_loss = session.run(avg_tensor)
auc = session.run(auc_tensor)
auc_eval = session.run(auc_eval_tensor)
acc = session.run(acc_tensor)
acc_eval = session.run(acc_eval_tensor)
session.run(reset_ops)
tf.summary.FileWriterCache.clear()
if last_print:
print('Last average loss: {:.3f}'.format(avg_loss))
print('Last AUC: {:.3f}, eval {:.3f}'.format(auc, auc_eval))
print('Last accuracy: {:.2f}, eval {:.2f}'.format(
100 * acc, 100 * acc_eval))
Treinamento do Classificador de Sentimento:
%%timeé uma diretiva do Jupyter para medir o tempo de execução de uma célula - caso a execução desse código não seja no Jupyter, é necessário remover essa linha.
%%time
collection_size = len(document_to_id)
embedding_size = 25
batch_size = 16
valid_X, valid_y = zip(*valid_data)
valid_X = np.reshape(valid_X, (-1, 1))
valid_y = np.reshape(valid_y, (-1, 1))
eval_data = (valid_X, valid_y)
model_fn = lambda: model_sentiment(collection_size,
embedding_size)
input_fn = lambda: input_sentiment(train_data,
batch_size)
train_sentiment_pv(model_fn,
input_fn,
opt_ftrl,
[embeddings_dm, embeddings_dbow],
eval_data,
num_epochs=2,
model_dir='sent')
Last average loss: 0.659
Last AUC: 0.646, eval 0.654
Last accuracy: 60.14, eval 60.87
CPU times: user 3.87 s, sys: 308 ms, total: 4.18 s
Wall time: 2.87 s
Avaliação do Teste:
%%timeé uma diretiva do Jupyter para medir o tempo de execução de uma célula - caso a execução desse código não seja no Jupyter, é necessário remover essa linha.
%%time
collection_size = len(document_to_id)
embedding_size = 25
batch_size = 16
test_X, test_y = zip(*test_data)
test_X = np.reshape(test_X, (-1, 1))
test_y = np.reshape(test_y, (-1, 1))
eval_data = (test_X, test_y)
embeddings = [embeddings_dm, embeddings_dbow]
with tf.Graph().as_default() as graph, \
tf.Session(graph=graph) as session:
init, inputs, predictions, loss_op = \
model_sentiment(collection_size,
embedding_size)
_, y = inputs
y_prob, y_hat = predictions
EPOCH_SUMMARIES = 'epoch_summaries'
avg_tensor, avg_op, avg_reset = \
metrics_average_loss(loss_op, EPOCH_SUMMARIES)
auc_eval_tensor, auc_eval_op, auc_eval_reset = \
metrics_auc('eval', y, y_prob, EPOCH_SUMMARIES)
acc_eval_tensor, acc_eval_op, acc_eval_reset = \
metrics_accuracy('eval', y, y_hat, EPOCH_SUMMARIES)
eval_feed = dict(zip(inputs, eval_data))
saver = tf.train.Saver()
saver.restore(session, tf.train.latest_checkpoint('sent'))
session.run(tf.local_variables_initializer())
init_feed = dict(zip(init[0], embeddings))
session.run(init[1], init_feed)
session.run([avg_op, auc_eval_op, acc_eval_op], eval_feed)
avg_loss = session.run(avg_tensor)
auc_eval = session.run(auc_eval_tensor)
acc_eval = session.run(acc_eval_tensor)
print('Average loss: {:.3f}'.format(avg_loss))
print('AUC: {:.3f}'.format(auc_eval))
print('Accuracy: {:.2f}'.format(100 * acc_eval))
Average loss: 0.646
AUC: 0.674
Accuracy: 63.53
CPU times: user 393 ms, sys: 81.6 ms, total: 475 ms
Wall time: 369 ms
Na sequencia, a análise de resultados usando TensorBoard.
…
Resultados
A análise desse trabalho consiste na execução de diferentes combinações de configurações para os três modelos, DM, DBOW e Classificador de Sentimento.
Os resultados mostrados são da execução do treinamento feita no Notebook.
São 4 configurações alterando os parâmetros de Tamanho da Janela (window_size) e Combinação do DM (average ou concatenate). O Tamanho da Representação (embedding_size) foi alterada na primeira versão da análise e mantida como ‘parâmetro’, mas os resultados foram removidos da versão final por simplicidade.
Cada configuração é treinada por 25 épocas no total para os modelos do Paragraph2vec, intercaladas com 2 épocas dos modelos do classificador de sentimento. No total são 5 modelos: DM, DBOW, Classificador só com DM, Classificador só com DBOW e Classificador com DM e DBOW (concatenado).
As métricas para análise são:
Average loss- Erro Médio por época para cada modelo (5 séries por configuração).Accuracy/Train- Acurácia no Treino por época para os modelos do Classificador (3 séries por configuração)Accuracy/Eval- Acurácia na Validação por época para os modelos do Classificador (3 séries por configuração)AUC/Train- AUC ROC no Treino por época para os modelos do Classificador (3 séries por configuração)AUC/Eval- AUC ROC na Validação por época para os modelos do Classificador (3 séries por configuração)
Configuração por execução:
25_2_avgembedding_size=25, window_size=2 dm_linear=average25_4_avgembedding_size=25, window_size=4 dm_linear=average25_2_concatembedding_size=25, window_size=2 dm_linear=concatenate25_4_concatembedding_size=25, window_size=4 dm_linear=concatenate
Configuração comum:
num_iters=25collection_size=239_232vocabulary_size=19_214num_sampled=100batch_size=64
Erro Médio:
O primeiro gráfico mostra o Erro Médio para o DM nas diferentes configurações de janela e combinação dos vetores. O valor diminui com o tempo para todas as configurações sendo que o menor valor é obtido com a configuração 25_4_concat com valor de 0,5.
O segundo gráfico mostra o Erro Médio para o DBOW que só varia com o tamanho da janela. O menor valor obtido foi com as configurações de janela com tamanho 2, 25_2_avg e 25_2_concat.
O terceiro gráfico mostra o Erro Médio para o Classificador de Sentimento, somente para o modelo que concatena os vetores do DM e DBOW. A variação não é muito grande (mínimo em 0,63 e máximo em 0,66) e o menor valor é da configuração 25_2_avg.
Os resultados são consistentes, o erro diminui sem oscilação indicando que o modelo melhora o desempenho nos dados do treino. Agora é importante saber se essa diminuição tem impacto na tarefa de classificação de sentimento.
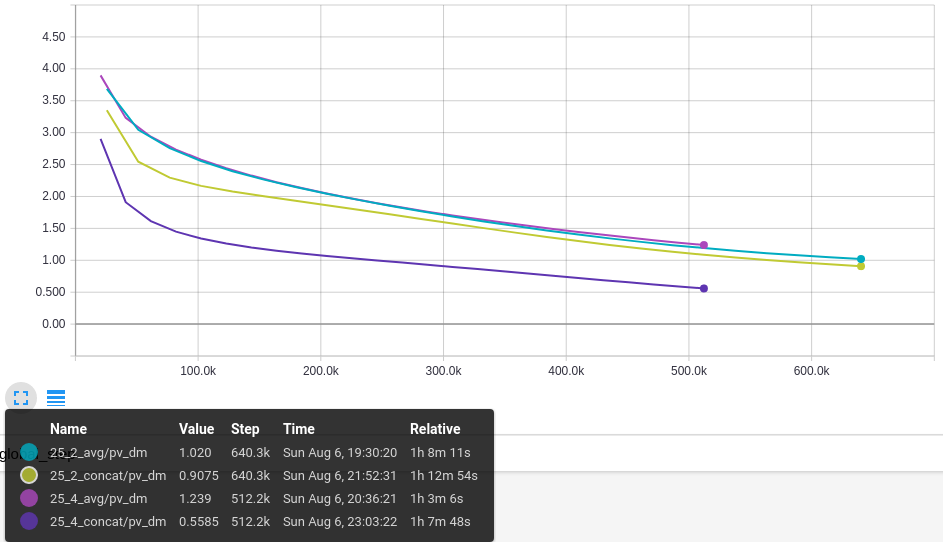
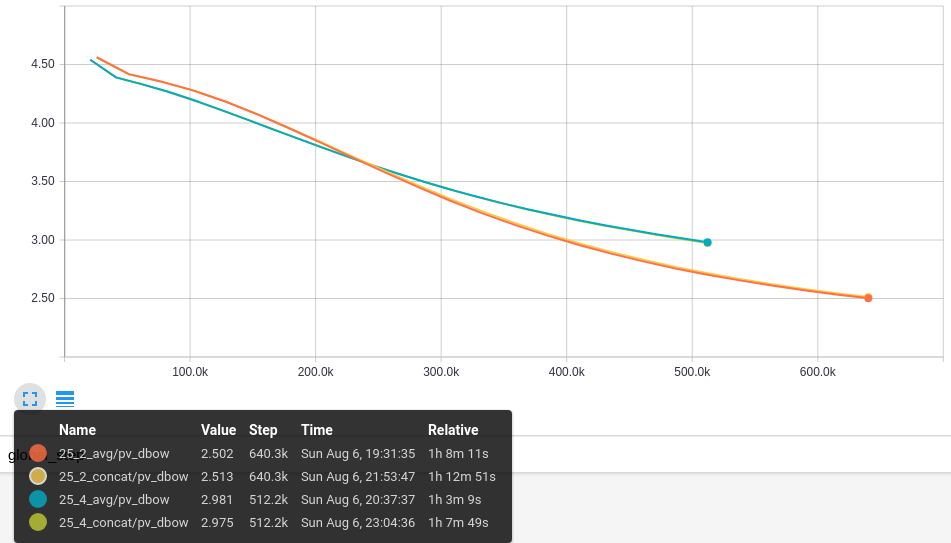
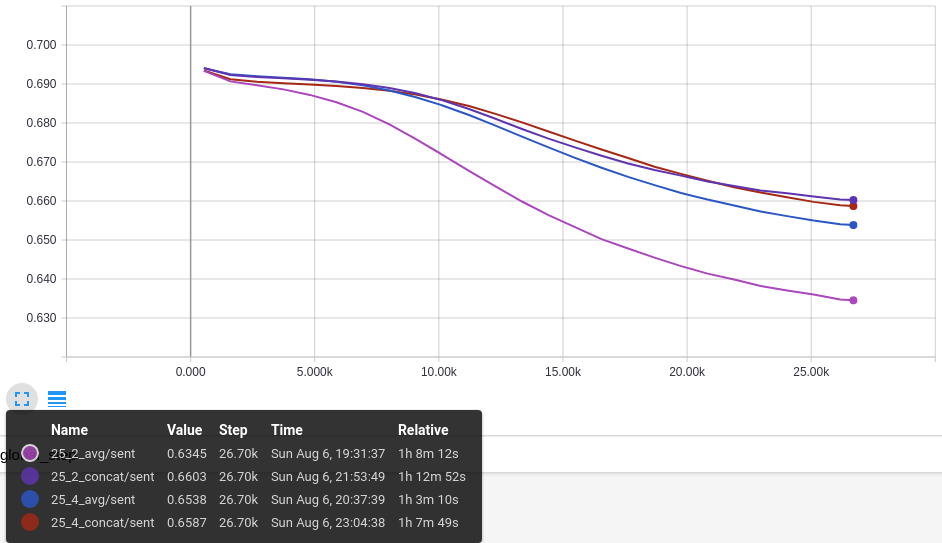
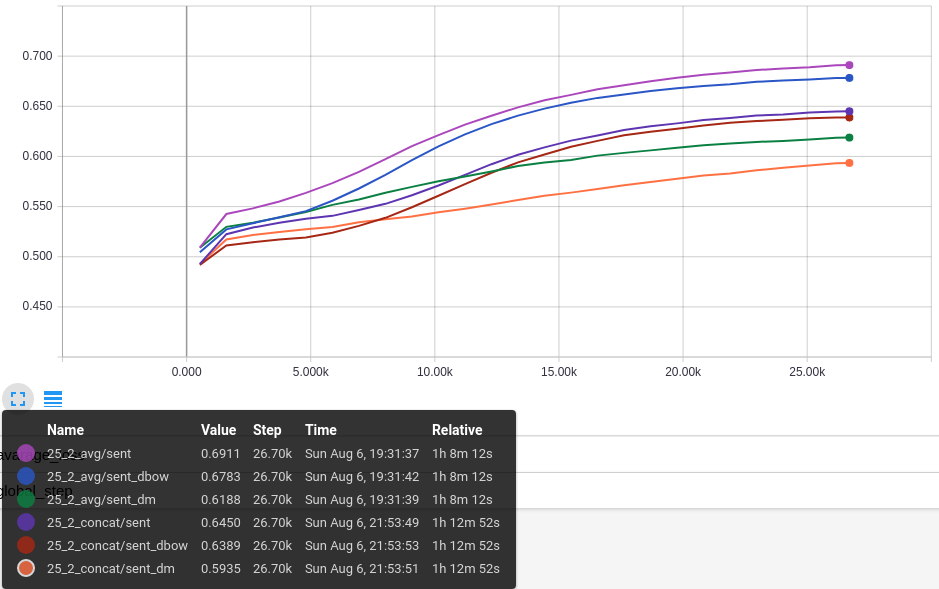
Accuracy:
Para essa análise, foram selecionadas as duas configurações que obtiveram melhor resultado na Acurácia de Validação: 25_2_avg e 25_2_concat. Portanto, o melhor desempenho nessa análise é com o Tamanho de Janela menor.
O primeiro gráfico mostra a Acurácia no dataset de Treino para os 3 modelos do Classificador, nas 2 configurações. O melhor resultado é da configuração 25_2_avg para o modelo com vetores concatenado, com 0,64. O segundo melhor é o modelo da mesma configuração que usa somente o DBOW com 0,63. O modelo que usa somente o DM dessa configuração não obteve um resultado bom, ficando com 0,58. Contudo, como o resultado da combinação é superior, isso indica que há contribuição positiva (complemento) com a informação gerada com o DM. Esse gráfico também mostra um problema, dado que ambas as configurações tem os mesmos parâmetros para o DBOW, os resultados deveriam ser próximos, mas na configuração 25_2_concat, o valor é 0,60 (a análise desse problema fica como tarefa para o futuro).
O segundo gráfico mostra a Acurácia no dataset de Validação. Os resultados são similares ao Treino, indicando que o aprendizado não está apenas decorando e realmente tem alguma generalidade.
Esses gráficos mostram o princípio que era o objetivo desse trabalho: o aprendizado não supervisionado feito com Paragraph2vec, independente da tarefa de Análise de Sentimento, realmente preserva características do texto que podem ser usadas como features em tarefas que dependem do sentido do texto.
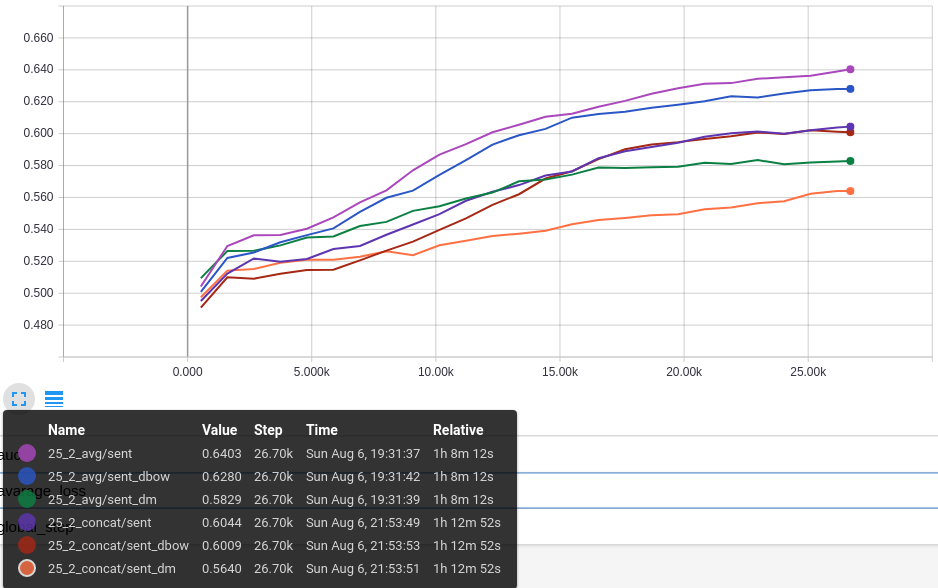
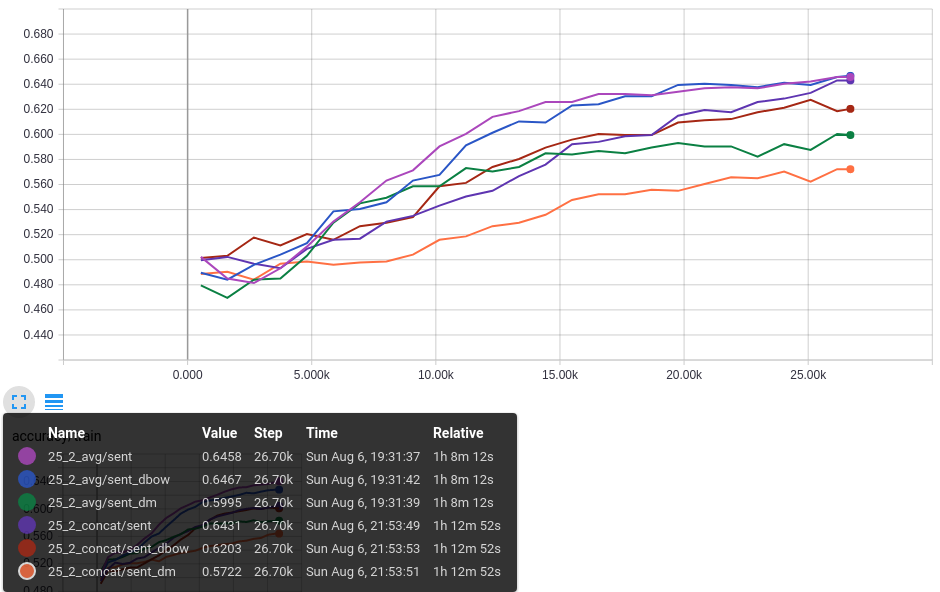
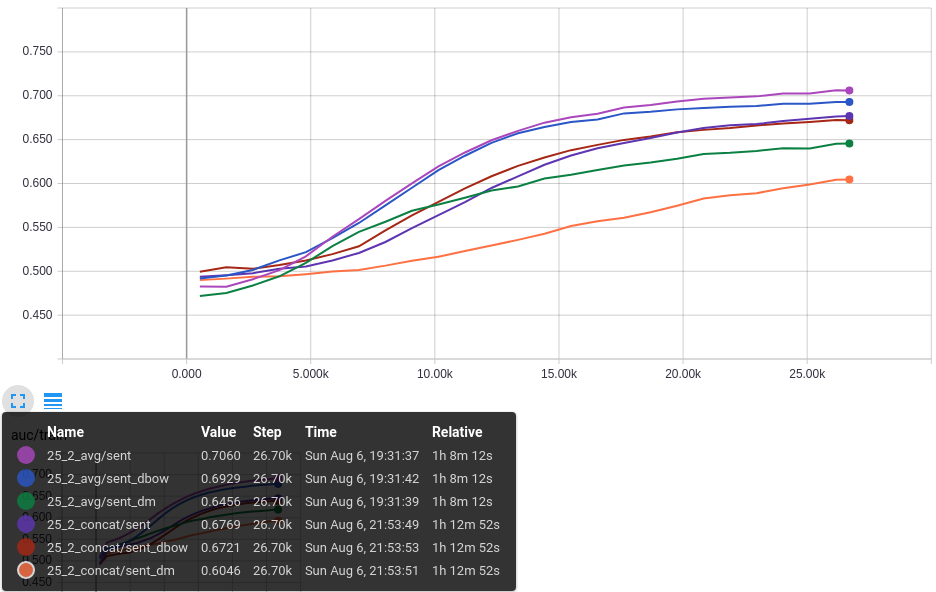
AUC:
As mesmas configurações usadas na análise da Acurácia são mostradas na métrica da AUC ROC. Os resultados são consistentes com a Acurácia, indicando que o aprendizado não aprende somente a distribuição das classes do dataset e realmente é preditivo.
O primeiro gráfico mostra a AUC ROC no dataset de Treino.
O segundo gráfico mostra a AUC ROC no dataset de Validação.
…
Ao final do procedimento descrito inicialmente nesse tópico, 3 resultados são produzidos:
{pv_dm,pv_dbow,sent}- uma pasta por modelo do checkpoint com os resultados do treinamento, podem ser usados para análises e novas iterações do treinamento
Esse é o resultado final desse trabalho.
Conclusão
Word2vec mostrou que modelos simples de aprendizado não supervisionado podem ter propriedades muito úteis na compreensão de texto em linguagem natural. Paragraph2vec avança essa ideia propondo modelos similares que possibilitam a construção de representação vetorial para documentos, de sentenças curtas a múltiplos parágrafos. Esses vetores preservam significado do texto em que o aprendizado é feito e podem ser usados como features para modelos que mapeiam relações desses valores em uma tarefa que depende do sentido que o texto expressa.
A proposta desse trabalho foi fazer a implementação com TensorFlow e mostrar esse princípio, aprendizado de uma representação vetorial que serve à análise de sentimento em modelos separados. Os resultados mostrados não reproduzem o estado-da-arte apresentado no paper, mas mostram como é possível implementar esses modelos. Para reprodução dos resultados, seria necessário uma técnica mais elaborada. Atingir esses resultados seria uma tarefa para o uso pático desses modelos (ou publicação de paper).
O Gensim é uma ferramenta que oferece uma implementação do Paragraph2vec com a qual é possível obter resultados muito bons. Veja mais no tutorial da Análise de Sentimento do dataset do IMDB (link).
Uma limitação do Paragraph2vec é que, para aprender a representação vetorial de novos documentos, é necessário executar o processo de treino aumentando a matriz de vetores de documentos. Esse é um processo oneroso dependendo da variedade do conteúdo e da dinâmica em que os documentos são produzidos.
Nos próximos artigos, a proposta é mostrar as técnicas mais interessantes de Deep Learning para NLP, a começar pelo LSTM, com o qual é possível obter o vetor de um novo documento sem fazer um novo treinamento.
Referências
Distributed Representations of Sentences and Documents (Paragraph2vec paper)