A proposta desse artigo é fundamentar alguns conceitos de BigData e explorar a dinâmica de como tratar um grande volume de dados para extrair valor. A ideia é apresentar a solução de dados na Plataforma de BigData da Globo.com usada pelo Sistema de Recomendação e comentar a experiência do seu desenvolvimento.
Esse artigo é uma atualização e expansão da palestra realizada no Rio BigData Meetup em 21 de Outubro de 2014.
Os slides originais dessa palestra podem ser acessados aqui.
Personalização
A Globo.com é a empresa de Internet do Grupo Globo e tem alguns dos maiores portais do Brasil (G1, Globo Esporte, GShow e Vídeos). São dezenas de milhões de acessos por dia aos portais com cerca de 10 milhões de visitantes únicos e uma produção massiva de conteúdo bastante variado em Jornalismo, Esporte, Variedades e Vídeos (juntamente com TV Globo, Editora Globo e demais empresas do Grupo).
Com a proposta de personalizar o conteúdo da Globo.com nos diversos produtos que formam cada portal, o time de Personalização foi criado a um pouco mais de 2 anos e meio. Esse time recebeu o desafio de implementar um Sistema de Recomendação que pudesse recomendar para milhões de usuários ativos milhares de itens variados (notícias, vídeos, filmes, …).
A Plataforma de BigData da Globo.com surgiu dessa experiência.
Recomendação
O Sistema de Recomendação é projetado para coletar os sinais produzidos tanto pela dinâmica do usuário quanto pela dinâmica do conteúdo e filtrar o que é relevante para o usuário no momento em que isso é importante.
Nesse sistema, os dados coletados são processados e transformados em modelos de Usuário, Conteúdo e Contexto. Esses modelos são usados para apresentar as melhores opções de acordo com parâmetros do Produto. A interação do usuário com o conteúdo recomendado é avaliada através de testes usados para orientar constantes mudanças em busca de melhorar a performance do sistema.
A plataforma desenvolvida na Globo.com para recomendação personalizada de conteúdo é projetada para suportar milhões de usuários ativos, milhares de itens variados em fluxo, diversos contextos de produtos.
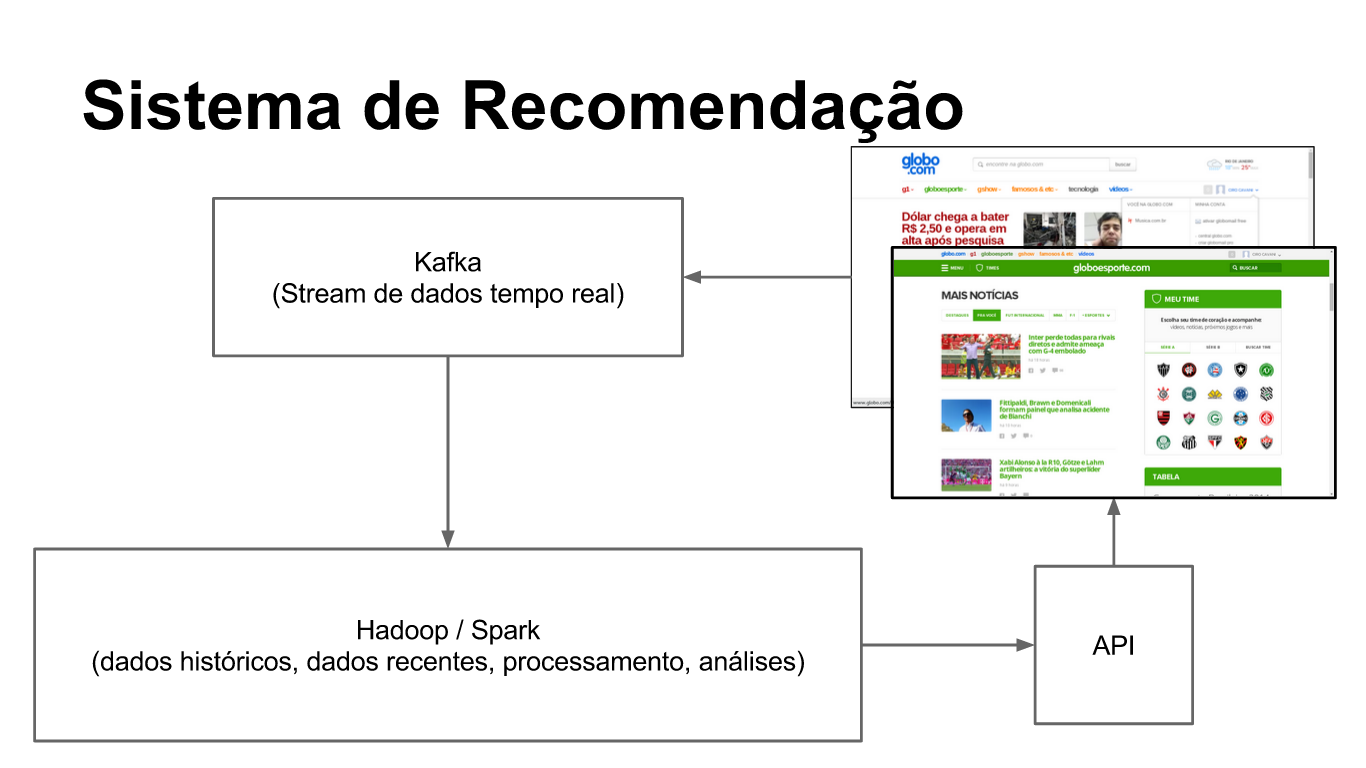
Essa plataforma pode ser dividida em três partes: recebimento de dados em tempo real, processamento de algoritmos de recomendação, e; consulta on-line com combinação de modelos.
O processo de recebimento de dados em tempo real é baseado no Kafka, um cluster de distribuição de mensagens de alta performance que suporta bilhões de mensagens por dia. Esse sistema é usado para receber todos os sinais coletados sobre o usuário possibilitando o processamento stream em tempo real. Eventualmente, esse stream é armazenado permanentemente no cluster Hadoop para processamento em lote e análise.
O processo dos algoritmos de recomendação varia para cada caso. Um caso típico é o processamento em três etapas no cluster Hadoop. Na primeira etapa, é feito um condicionamento de dados novos, seja para transformar em um formato específico ou para atualizar um pré-modelo gerado na última execução. Na segunda etapa, é executado o algoritmo de recomendação. Na terceira etapa, o resultado do algoritmo é verificado e transformado no formato que pode ser consultado. Normalmente a execução é condicionada por vários parâmetros e é comum ter diferentes configurações do mesmo algoritmo em teste.
A consulta on-line é a API que os desenvolvedores da Globo.com podem usar para recomendar conteúdo personalizado. A API faz a combinação dos diversos modelos de recomendação e filtra o conteúdo mais relevante para o usuário. A API permite criar testes A/B com combinações diferentes dos modelos permitindo avaliar a performance de um algoritmo contra outro, ou o mesmo com parâmetros diferentes.
Um exemplo de como esse sistema funciona:
(esse exemplo captura a essência, mas é só uma ilustração)
Collaborative Filtering por Fatores Latentes usando Spark
Toda vez que uma página da Globo.com é visitada, é gerado um sinal de pageview com o id do usuário, a URL e o timestamp. Esse sinal passa pelo Kafka e é armazenado no Hadoop. Um job Spark varre todos os sinais não processados na última execução (timestamp) gerando um arquivo com o formato user-item-rating (rating = número de visitas, por simplicidade) correspondendo a matriz de Preferências. Outro job Spark é executado para processar a matriz de Preferências, fazer a fatoração e gerar os vetores de fatores latentes por usuário e item. Os fatores latentes são usados para calcular os scores (ratings) não observados (itens não vistos pelo usuário) e os 30 maiores são armazenados no HBase. Quando configurada para esse algoritmo, a API consulta o HBase e usa a lista com score para combinar com outros resultados e fazer a recomendação.
Tecnologia
A revolução em BigData é um fenômeno da tecnologia desenvolvida ao longo dos últimos anos focada na manipulação de um grande volume de dados em máquinas de baixo custo. Essa é a tecnologia que torna possível combinar uma solução de dados escalável com processos para geração de resultados relevantes, tanto no desenvolvimento de produtos quanto na evolução do conhecimento. O importante é entender como essa tecnologia pode ser usada para agregar valor ao negócio e permitir imaginar soluções inovadoras.
A Globo.com tem Data Center próprio e a instalação do cluster de BigData foi feito em máquinas físicas. Esse cluster é composto por um conjunto maior de máquinas com Hadoop e HBase e outro conjunto menor de máquinas com Kafka e ZooKeeper. O principal framework que usamos é o Spark, mas ainda temos alguns scripts Pig de processos antigos (legado). É um cluster de média capacidade que deve crescer com o tempo / necessidades.
Em artigos futuros, entrarei em mais detalhes sobre como usar essas tecnologias.
Hadoop
![]()
O Hadoop torna o custo por byte de armazenamento / processamento marginal e por isso torna BigData possível na escala de hoje. O problema que o Hadoop resolve é de otimizar a utilização de múltiplas máquinas por vários processos.
Com o Hadoop é possível ter escalabilidade horizontal, alta taxa de utilização (CPU/Memória) e tolerância a falhas com máquinas de baixo custo para armazenar e processar dados. Um processo que é dimensionado inicialmente para um certo volume pode ser escalado colocando mais máquinas no cluster, muitos processos podem compartilhar esse cluster sem preocupação de sobrecarga, ociosidade ou interferência e a perda de máquinas ou falhas de disco não resultam em indisponibilidade ou perda de dado.
O paradigma essencial é partir da premissa de que máquinas de baixo custo não são confiáveis e que é mais eficiente levar o processamento para onde o dado fica armazenado do que movimentar dados. O Hadoop é um sistema que foi desenvolvido com essa essência.
O Hadoop é um sistema de arquivos distribuído (HDFS) e um sistema de execução distribuído (YARN), de outra forma, é essencialmente um sistema operacional para um cluster de máquinas onde dados são armazenados e processados. O processamento de dados é feito através de aplicações que fazem uso das APIs desses sistemas, contudo elas são mais elementares. Existem vários frameworks que são abstrações dessas APIs e oferecem modelos de programação mais elaborados, com funcionalidades mais avançadas.
O framework original do Hadoop é o MapReduce voltado para processamento em lote com grande latência. Pig é uma ferramenta que permite escrever scripts em uma linguagem alto nível de manipulação de dados; os scripts são compilado para Java (byte-code) e executados no Hadoop na forma de vários jobs MapReduce. Essa é a tecnologia que usamos no início de BigData na Globo (Recomendação e Busca). Contudo, MapReduce é uma tecnologia que está sendo abandonada - o Google, seu criador, anunciou há algum tempo que deixou de usar MapReduce e passou a usar a tecnologia do Dataflow (oferecida ao grande público como Cloud Dataflow).
Por outro lado, a indústria também vem abandonando o MapReduce e, entre várias opções, duas tecnologias estão em evidência: Spark e Tez. O Spark apresenta uma API simples de operações sobre coleções de dados, internamente constrói um grafo de tarefas que são executadas em blocos de memória distribuídos; suporta SQL, Machine Learning, Streaming e Processamento de Grafos; está sendo usado como engine para diversas ferramentas analíticas (Mahout, por exemplo). O Tez é mais baixo nível e encapsula a construção de grafos de execução que podem ser otimizados dinamicamente; é usado principalmente como engine em ferramentas mais elaboradas (Hive e Pig, por exemplo). Uma terceira tecnologia que pode ganhar tração é o Flink, também segue o princípio de API simples, construção de plano de execução, otimização.
…
O HDFS é composto por dois serviços: o NameNode que mantém o índice de arquivos e o mapeamento desses arquivos para os blocos de dados distribuídos pelo cluster (roda em uma máquina); e o DataNode que armazena os blocos de arquivo (roda em todas as máquinas). Um arquivo pode ser dividido em vários blocos e cada bloco ainda é replicado em 3 DataNodes. O NameNode controla as operações de manipulação de arquivo, mas as operação de leitura e escrita são feitas diretamente com os DataNodes. A perda do DataNode não resulta em perda de dados e o número de réplicas é sempre ajustado. As réplicas também são usadas para o acesso local aos dados por processos paralelos.
O YARN é composto por dois serviços: o ResourceManager que mantém registro e controla a alocação de memória e processador das máquinas do cluster (roda em uma máquina); e o NodeManager que controla os container de execução de uma aplicação (roda em todas as máquinas). Um terceiro serviço é o ApplicationMaster associado a cada aplicação que roda no cluster e negocia com o ResourceManager a alocação de recursos providas nos NodeManagers. Um framework como Spark roda como um ApplicationMaster que cria containers ‘workers’ para processar os dados em memória. MapReduce segue esse mesmo princípio, criando containers de Mappers e Reducers. Também é possível rodar aplicações standalone como HBase e Kafka usando YARN.
Hadoop
https://hadoop.apache.org/Spark
https://spark.apache.org/Flink
https://flink.apache.org/MapReduce and Spark (30/Dez/2013)
http://vision.cloudera.com/mapreduce-spark/Google Cound Dataflow
https://cloud.google.com/dataflow/The Google File System (Out/2003)
http://research.google.com/archive/gfs.html
http://research.google.com/archive/gfs-sosp2003.pdfMapReduce: Simplified Data Processing on Large Clusters (Dez/2004)
http://research.google.com/archive/mapreduce.html
http://research.google.com/archive/mapreduce-osdi04.pdfApache Hadoop YARN: yet another resource negotiator (Out/2013)
http://www.socc2013.org/home/program/a5-vavilapalli.pdf
HBase
![]()
O HBase é um banco de dados sem esquema que suporta bilhões de linhas por tabela. Inspirado no paper BigTable do Google, suporta uma estrutura chave-valor ordenada, multidimensional, esparsa, distribuída e persistente. O principal benefício é o suporte para operação eficiente com pequenos blocos de bytes em complemento ao HDFS que opera melhor com grandes blocos.
O HBase opera como um cluster distribuído tolerante a falhas. A leitura e escrita são consistentes, a consulta pela chave tem baixa latência e suporta um grande número de operações concorrentes. Contudo, sua API é limitada a operações simples (put, get, scan, array de bytes) e estendida com processadores executados dentro do cluster (filter, coprocessor). Não tem suporte nativo para linguagem de consulta e também não suporta transação multi-chave.
Estruturar os dados no HBase conciliando performance de escrita, performance de leitura e representação expressiva é um grande desafio. Os dados tem índice único pela chave da tabela e a performance depende da distribuição dessas chaves entre os servidores.
O Phoenix é uma solução complementar ao HBase com suporte a índices secundários e consultas SQL. O Phoenix opera dentro do HBase (coprocessador) e do lado da aplicação, fazendo a intermediação das operações de leitura e escrita condicionando os dados. A modelagem de dados fica acoplada com a ferramenta. A API para aplicação que usa o Phoenix é um driver JDBC, incluindo suporte para esquema e dados ‘tipados’ (não só bytes).
O Spark tem suporte ao HBase através da API de Input/Output padrão do Hadoop ou direto com a API do HBase. Ou seja, são operações simples para leitura e escrita, mas não consulta mais elaboradas. O HBase ainda não é suportado pelo Spark SQL / Catalyst, framework para processamento de dados estruturados com suporte a execução e otimização de consultas SQL e operações em tabela (DataFrame). Esse é um projeto em andamento e vai possibilitar que consultas complexas sejam otimizadas, minimizando a movimentação de dados e transferindo parte do processamento para o HBase.
O HBase tem papel fundamental como intermediário entre as aplicações que fazem processamento de grandes volumes de dados e aplicações que fazem acesso a dados específicos. O caso de uso principal em que usamos o HBase é para o armazenamento de resultados que podem ser usados externamente ao Hadoop. Isso diminui a movimentação de grande volumes de dados para sistemas externos e mantém a baixa latência necessária para uso externo.
O Google, criador do BigTable que inspirou o HBase, acabou ‘desistindo’ dessa tecnologia e implementando um sistema mais complexo com suporte a operações transacionais em larga escala. Esse sistema chama-se Spanner e tem muitos dos princípios originais do BigTable, mas com suporte a serialização global de operações. Para manter esse sincronismo, são usados relógios atômicos e GPS de precisão. Apesar de ser um ‘sucessor’ do BigTable no Google, dificilmente vai tornar obsoleto o HBase ou inspirar um novo banco (eu posso estar errado aqui!).
…
O HBase é composto por dois serviços: o HMaster monitora os RegionServers, distribui as Regiões de Dados (Splits, bloco de Linhas de uma Tabela) e recebe operações de DDL, e; o RegionServer mantém Regiões de Dados em um DataNode / HDFS, recebe acesso direto dos Clientes para operação de leitura/escrita. O ZooKeeper é usado para metadados / configurações. Escalabilidade através da adição de servidores (RegionServers).
O RegionServer tem um WAL (Write Ahead Log), um BlockCache e várias Regiões de Dados. Cada Região tem vários Armazenamentos (Store), um por Família, cada um com vários arquivos (HFile) e um Armazenamento em Memória (MemStore). O WAL e os HFiles são persistidos no HDFS. Os arquivos de dados (HFiles) são reescritos de tempos em tempos para obter localidade e ajustar automaticamente a performance.
HBase
https://hbase.apache.org/Phoenix
https://phoenix.apache.org/Spark SQL on HBase
https://github.com/Huawei-Spark/Spark-SQL-on-HBaseSlider
https://slider.incubator.apache.org/
https://wiki.apache.org/incubator/SliderProposalBigtable: A Distributed Storage System for Structured Data (Nov/2006)
http://research.google.com/archive/bigtable.html
http://research.google.com/archive/bigtable-osdi06.pdfSpanner: Google’s Globally-Distributed Database (Out/2012)
http://research.google.com/archive/spanner.html
http://research.google.com/archive/spanner-osdi2012.pdf
Kafka
![]()
O Kafka é um cluster de distribuição de mensagens que escala para um grande número de produtores e consumidores. Criado pelo LinkedIn, o Kafka tornou-se a tecnologia fundamental para uma arquitetura de dados stream. Com o Kafka, é possível concentrar e distribuir um fluxo muito grande de dados que podem ser acessados tanto para processamento em tempo real quanto para processamento em lote. O principal benefício é o acesso direto ao dado quase no mesmo instante em que ele é gerado.
O Kafka opera como um cluster distribuído tolerante a falhas. É baseado no modelo Publish-Subscribe e essencialmente funciona como um ‘append-only log’, com novas mensagens adicionadas no final de cada arquivo e leitura sequencial. As aplicações podem enviar mensagens para um determinado tópico; os servidores recebem essas mensagens e as armazenam em arquivos, e as aplicações podem pegar essas mensagens por tópico em qualquer momento (tempo real ou lote). Por ‘concepção’, as funcionalidades são bastante limitadas e orientadas para suportar um fluxo grande de mensagens.
O Kafka se destaca em: Performance, com alto throughput no recebimento e distribuição; Escalabilidade, muitos consumidores, isolamento entre consumidores, e; Mensagens pequenas, não estruturadas / opacas (bytes).
O Spark Streaming tem suporte ao Kafka como fonte de dados. São duas APIs, a de Receivers que consome constantemente mensagens e armazena na aplicação e a Direta que mapeia os offsets das mensagens e faz consumo por intervalo (do mini-batch) - a API Direta é mais específica e melhor com o Kafka. A partir do stream do Kafka, é possível processar os dados usando as funcionalidades sofisticadas do Spark. Um caso de uso é o armazenamento em lote de arquivos Parquet para consulta histórica. Outro exemplo é o processamento de janelas para a geração de métricas em tempo real (conversão, visualizações). O Spark é a ferramente ideal para o processamento e análise dos dados distribuídos pelo Kafka.
Com o Kafka, a gente construiu um sistema de coleta de atividades. Seu propósito é tornar possível receber, distribuir e armazenar toda e qualquer informação sobre o usuário escalando para bilhões de mensagens por dia trafegando pelo sistema. Nesse sistema trafegam as páginas visitadas, vídeos assistidos, buscas, comentários, compartilhamentos, track da página, … todos esses dados são processados e armazenados no HDFS no formato Parquet. Simultaneamente, esse dados são usados em vários outros sistemas, Recomendação e Busca entre eles. Essa arquitetura de dados vem se mostrando fundamental no desenvolvimento de soluções de dados inovadoras.
…
O Kafka é composto por três partes: o cluster de Brokers, a API do Produtor e a API do Consumidor. As APIs são usadas nas aplicações que se comunicam com o cluster e implementam o protocolo do Kafka. Implementações alternativas desse protocolo podem ser usadas para comunicação direta com o cluster.
Os Brokers organizam as Mensagens em Tópicos, podem ficar em memória temporariamente e são sincronizadas para disco de tempos em tempos, mantidas por tempo determinado (também pode ser limitada por espaço). Os Tópicos são divididos em Partições, cada uma com um arquivo em disco diferente. Os Tópicos podem ser replicados em vários Broker. Cada Broker gerencia um grupo de Tópicos. A perda de um Broker ou a corrupção de um arquivo de Partição não resulta em perda dos dados. Os Tópicos são criados com um nome único, número de Partições e número de Réplicas.
Produtores enviam Mensagens para um Tópico específico, para o qual é possível definir a Partição para distribuir a carga. Produtores também podem publicar mensagens de forma assíncrona, fazendo buffer em memória na aplicação. Consumidores precisam pegar mensagens de cada Partição, controlando o índice da mensagem consumida (offset). Ou seja, o número de Partições determina o paralelismo de consumo e o controle de consumo é responsabilidade da aplicação (o Broker não mantém controle do consumo).
Kafka
https://kafka.apache.org/Building LinkedIn’s Real-time Activity Data Pipeline (Jun/2012)
http://sites.computer.org/debull/A12june/pipeline.pdfThe Log: What every software engineer should know about real-time data’s unifying abstraction (Dez/2013)
http://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifyingSpark Streaming
httpd://spark.apache.org/streaming/Kafka on YARN (Slider)
https://github.com/DataTorrent/koya
https://slider.incubator.apache.org/
Spark
![]()
O Spark é um framework para processamento distribuído de grande quantidade de dados com foco em análise interativa. O Spark tem uma API simples que torna fácil escrever desde pequenas manipulações de dados, até algoritmos iterativos complexos, de forma escalável e com boas práticas de engenharia de software (testes). Essa característica o torna a ferramenta ideal de trabalho tanto para o Data Engineer que tem que desenvolver uma solução de dados, quanto para o Data Scientist que tem que desenvolver modelos e visualizações. Dessa forma, o Spark hoje é composto por um conjunto grande de funcionalidades com suporte DataFrame / SQL, Machine Learning, Streaming e Processamento de Grafos. Também é o projeto mais popular na área de BigData e cada nova versão adiciona ainda mais abrangência e inovação.
O projeto começou em Berkeley (pesquisa) como alternativa ao MapReduce para processar dados no cluster usando memória das máquinas como armazenamento entre etapas e vem evoluindo para ser um framework completo de analise de dados. Já fazem parte do projeto: o Spark SQL / DataFrame para processamento de dados estruturados, tabular; Spark ML / MLlib com uma pipeline de processamento e algoritmos de Machine Learning; o Spark Streaming para processamento de stream, mini-batches, diversas fontes como o Kafka, e; o GraphX para processamento de grafo, algoritmos de rede. Esses componentes são construídos sobre a mesma API básica do Spark e podem ser usadas em conjunto. Da proposta original aos componentes avançados, o Spark substitui o MapReduce completamente (o Tez é outra abordagem para substituir o MapReduce).
O MapReduce foi a solução original do Google para processamento de grande volume de dados com tolerância a falhas. O grande problema do MapReduce é a grande latência entre as diversas etapas de processamento que se baseiam em resultados intermediários armazenados no HDFS. Processamentos mais complexos são feitos através do encadeamento de vários jobs MapReduce (Pig faz isso). Esse modelo de execução escala bem, mas é bastante limitante para implementar algoritmos que fazem várias iterações sobre os mesmos dados, por exemplo. Esse é o cenário que fez o pessoal de Berkeley procurar uma nova solução que deu origem ao Spark.
O Spark apresenta uma API simples de operações sobre coleções de dados (RDD), internamente constrói um grafo de tarefas (DAG) que são executadas em blocos de memória distribuídos (Blocks). A ideia básica é carregar os dados em coleções imutáveis e aplicar transformações que resultam em novas coleções, no final, usar uma ação para materializar os resultados (como salvar em disco). Esse encadeamento de ações forma o grafo das transformações, contudo, a execução as tarefas em si é feita sob-demanda (lazy), os resultados intermediários são mantidos em memória e a perda dessa informação resulta na reexecução das tarefas necessárias para regerar o dado (ao invés de quebrar a aplicação). Dessa forma, o Spark é capaz de representar o processamento através de tarefas e usar a memória para comunicação entre essas tarefas, falhas de execução ou limpeza de memória fazem o grafo ser reprocessado, mantendo a garantia de tolerância a falhas e resiliência (ponto forte do MapReduce).
Na prática, o Spark facilita bastante o desenvolvimento de aplicações de processamento de dados mas ainda exige que o desenvolvedor dê grande atenção ao detalhes da aplicação, tendo que buscar soluções ‘eficientes’ para pontos críticos só identificados com carga. Com Spark, é possível escrever testes (funcionais) que rodam na Integração Contínua validando o comportamento da aplicação, contudo, quando submetido a carga de produção, a aplicação pode apresentar muitos erros difíceis de identificar o motivo (problema de memória, demora excessiva). A solução costuma ser analisar os logs / histórico, procurar as ineficiências, ajustar parâmetros, particionar, cachear, mudar algoritmos e/ou a ordem em que os dados são processados. Ou seja, além de escrever um código correto, é preciso que o código seja ‘dimensionado’ para os dados corretamente também.
O pessoal do Spark vem trabalhando em várias abordagem para resolver esses problemas. Uma primeira abordagem é a alocação dinâmica de ‘worker’ dando elasticidade a aplicação quando tem mais processamento e liberando recursos quando não é mais necessário. Uma segunda abordagem é oferecer uma abstração de dados mais estruturada que permite otimizar dinamicamente as manipulações de dados - o Spark introduziu o DataFrame que é uma tabela (ao invés de puramente uma coleção) que usa o Catalyst, um framework para processamento de dados estruturados que constrói um plano de execução e faz otimização para operações com a tabela e consultas SQL. Uma terceira abordagem é o esforço do Projeto Tungsten com objetivo trazer para o Spark funcionalidades de mais baixo nível, como representação compacta de dados em memória (evitando o GC da JVM), cache automático e geração dinâmica de código - nesse primeiro momento, o foco é o DataFrame / SQL. Por fim, de forma geral, uma abordagem é tornar a execução das tarefas ‘automaticamente’ mais eficientes através de heurísticas da execução - esse é um projeto que deve frutificar nas próximas versões do Spark. Hoje a recomendação é usar o DataFrame e deixar o framework executar de forma otimizada, e usar o RDD (coleção) quando isso não funcionar.
O Spark é o framework principal que a gente usa no processamento de dados. Com Spark Streaming, usamos para consumir mensagens no Kafka e persistir de forma permanente em Parquet no HDFS. Com Spark ML, usamos para construir a matriz de preferência do usuário-conteúdo e calcular a fatoração do modelo do usuário e do item para o Collaborative Filtering (ALS). Com Spark SQL / DataFrame construímos visualizações de métricas para avaliar os resultados dos testes A/B. Esses são alguns exemplos da versatilidade do Spark e de como ele é útil em uma Plataforma de BigData.
…
Uma aplicação feita com Spark pode rodar em um cluster do próprio Spark (standalone), no Mesos ou no YARN. A gente usa somente o YARN.
A execução da aplicação Spark é composta por dois componentes: o Driver que inicializa a aplicação, define o grafo de tarefas e as transformações e controla a execuções das tarefas, e; os Executors que armazenam blocos de dados em memória e executam as tarefas. Em um cluster YARN, o Spark tem duas formas de execução: uma em que o Driver é executada em uma máquina local e os Executores no cluster e a outra em que o Driver também é executado no cluster. No segundo caso, o launcher do Spark negocia com o ResourceManager um container para rodar o Driver. Esse conteiner é alocado pelo NodeManager e inicializado com o Driver. Em ambos os casos, o Driver negocia com o ResourceManager os containers dos Executores que são inicializados pelo NodeManager, nesse momento, eles sabem o endereço de volta do Driver e abrem a comunicação (os dados podem trafegar entre Driver-Executores e entre Executores). Nesse ponto em diante, o processamento começa.
O processamento em si é composto pelo grafo de tarefas que é construída a partir das transformações nas coleções de dados. A coleção que pode ser gerada a partir das transformações é chamada de RDD (Resilient Distributed Datasets) e é uma abstração lazy de um conjunto de dados. O resultado só é realmente materializado quando uma ação é executada no RDD, por exemplo, count ou collect. A materialização é feita através da análise de todas as tarefas do grafo de execução que precisam ser feitas para gerar esse resultado. Nesse momento, o Driver passa a enviar tarefas para os executores e armazenar os resultados nos Blocos de memória de cada Executor. Um RDD materializado é representado em partições que ficam distribuídas nos Executores. No momento em que novos RDDs são materializados, os antigos vão sendo desalocados, contudo, caso os dados sejam novamente necessários, o Driver reexecuta as tarefas para materializar esses resultados. É possível fazer cache dos dados materializados, tanto em memória quanto em disco, evitando assim o reprocessamento.
Essa é a base do modelo de execução do Spark que é estendido pelas outras ferramentas do pacote, DataFrame / SQL com Catalyst, Spark Streaming com DStream e os mini-batches, as pipelines e algoritmos de Machine Learning e o processamento de grafos do GraphX.
Spark
https://spark.apache.org/Provide elastic scaling within a Spark application
https://issues.apache.org/jira/browse/SPARK-3174Projeto Tungsten
https://issues.apache.org/jira/browse/SPARK-7075Adaptive execution in Spark
https://issues.apache.org/jira/browse/SPARK-9850Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing (2012)
http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdfDiscretized Streams: A Fault-Tolerant Model for Scalable Stream Processing (2012)
http://www.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-2012-259.pdf
Conclusão
Esse artigo é a catarse de um pouco mais de 2 anos de trabalho feito pelo time de Personalização no desenvolvimento do Sistema de Recomendação. Esse trabalho teve início com um grupo de cerca de 5 pessoas e, com alguma troca, se manteve nesse tamanho por grande parte do tempo. Há cerca de 9 meses, BigData ganhou internamente em importância e foi criada uma área dentro da empresa com esse foco. Onde antes tínhamos o Sistema de Recomendação como o único produto de dados dessa Plataforma de BigData, desse ponto em diante passamos a ter o desafio de tornar essa tecnologia disponível e útil para toda a empresa e todo o Grupo. Também estamos aumentando o time e planejando o crescimento para atender outros casos de uso. O mais importante dessa experiência é que construímos um conhecimento sólido para continuarmos desenvolvendo essa plataforma e expandir sua capacidade e valor dentro do Grupo.
Eu gostaria de pensar no futuro, e nesse sentido, a minha expectativa é que a gente construa na Globo.com uma plataforma similar ao Google Cloud Platform.
A gente vem de um modelo em que um mesmo time faz o desenvolvimento do Sistema de Recomendação, coleta e processamento de dados, a análise e construção de modelos, e a gestão da Plataforma de BigData. A proposta é expandir cada uma dessas responsabilidade em times próprios e adicionar outros com foco em suportar novas demandas. É nesse processo que nos encontramos nesse momento.
…
Meu interesse pessoal é Inteligência Artificial e, alinhado com os avanços que vem sendo feitos na área, BigData é muito importante para o desenvolvimento dos modelos que estão produzindo os melhores resultados. De outra forma, também é válido dizer que a construção de agentes inteligentes é uma forma de tornar tratável uma quantidade muito grande de dados. Por uma formulação ou por outra, a ideia comum é que BigData e Inteligência Artificial tem uma intersecção importante.
Tem muita tecnologia nova sendo desenvolvida que propõe formas de tratar imagens, vídeo, linguagem natural na qual um algoritmo pode executar funções que hoje são feitas por pessoas. O que eu pretendo fazer é identificar onde essa tecnologia pode ser usada na Globo.com e trazer esse conhecimento.
Em específico, acredito que em algum momento teremos um time de Deep Learning para estudo e desenvolvimento de soluções novas usando BigData.
Esse é o tema do meu Mestrado e no futuro, trarei mais material sobre o assunto.
comments powered by Disqus